
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 방콕여행
- 통계분석
- 딥러닝
- 리뷰
- 에어플로
- correlation
- 패캠챌린지
- 파이썬
- 태국여행
- 활성화함수
- 데이터 분석
- 빅데이터
- 상관분석
- 데이터분석
- API
- 자동매매프로그램
- Ai
- 분석
- 머신러닝
- DAGs
- 패스트캠퍼스
- 데이터
- Python
- airflow
- 직장인인강
- 패스트캠퍼스후기
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 독서리뷰
- 직장인자기계발
- EDA
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 21일차 본문
오늘은 챕터 2번째인 시계열 데이터 분석 강의가 시작되었다.
강의 실습 을 진행하기 전 기존에 시계열 데이터 전처리에 관련된 이론 부분을 한번 리마인드하고 가는 시간을 가졌다.
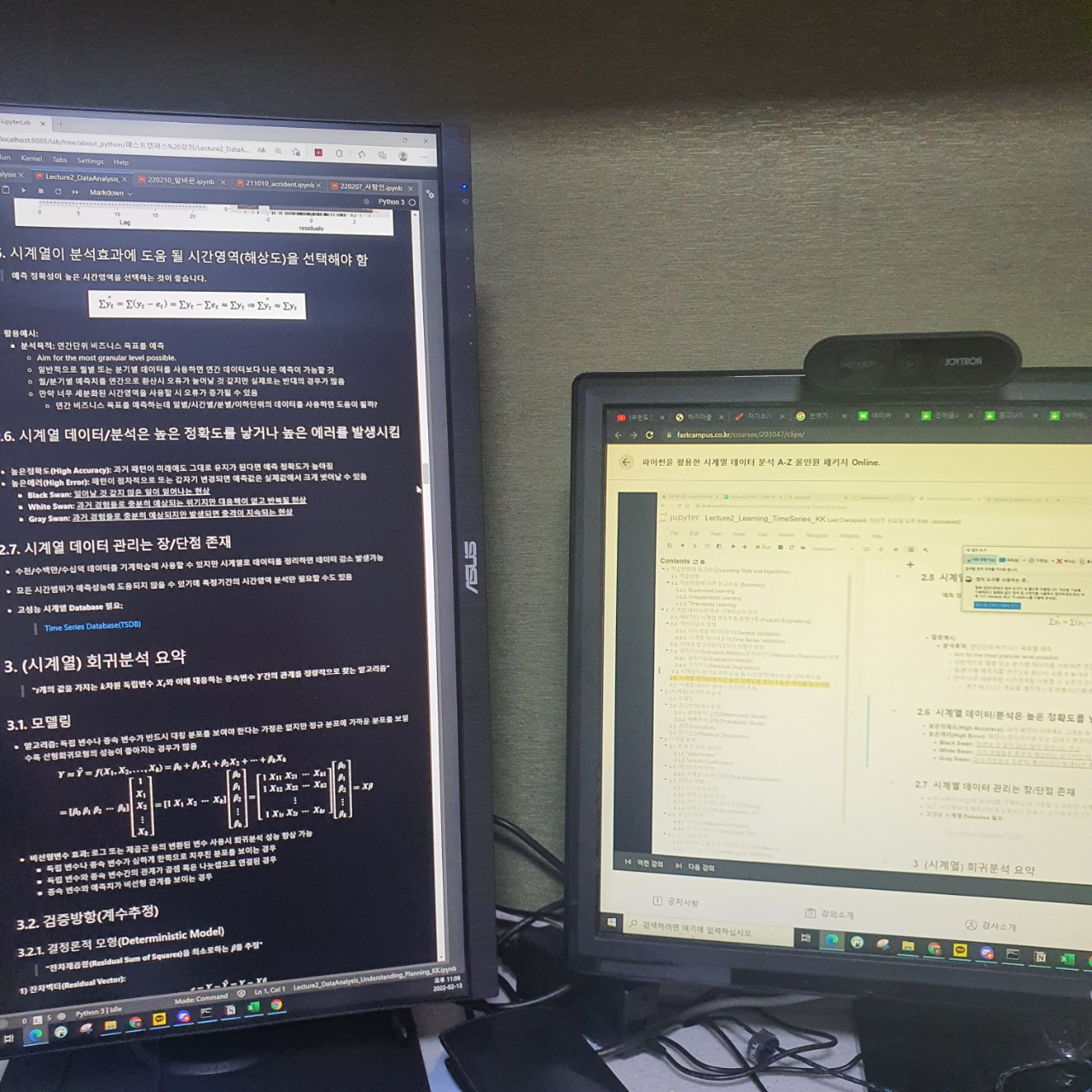
왼쪽화면은 강의자료화면이고 오른쪽은 강의화면이다.
데이터를 어떻게 파생변수로 만들어 사용하는 지 예시를 들어주었고 데이터 성향에 따라 파생 변수를 생성하는 방법이 다양하다.
홈쇼핑 데이터같은 경우 물품에 따라 계절성을 타는 물품들이 있으니 계절을 구분할 수 있는 파생변수를 만들어서 진행하고 분기별로 의미가 있는 데이터는 분기를 구분하는 파생 변수를 만드는 식으로 진행한다.
이번 강의에서는 시계열 데이터의 관리 부분도 알려주었다. Time series DB관리의 링크도 첨부하여 공부할 수 있도록 알려주었다.
시계열 데이터를 적재하다보면 동시간대의 데이터를 이용하여 분석하다보니 자연스레 데이터 감소가 일어난다. 그리고 시간 기준 별로 데이터를 구축하다보니 DB 관리의 어려움이 존재한다.
예를 들면 시간 간격으로 일 간격으로 각각의 데이터를 따로 테이블로 관리하려면 데이터의 양 자체가 많아져 DB가 무거워질 것이다. 이러한 어려움 때문에 위에서 시계열 데이터를 관리하는 법을 따로 알려주는 링크가 있었던 것이다.
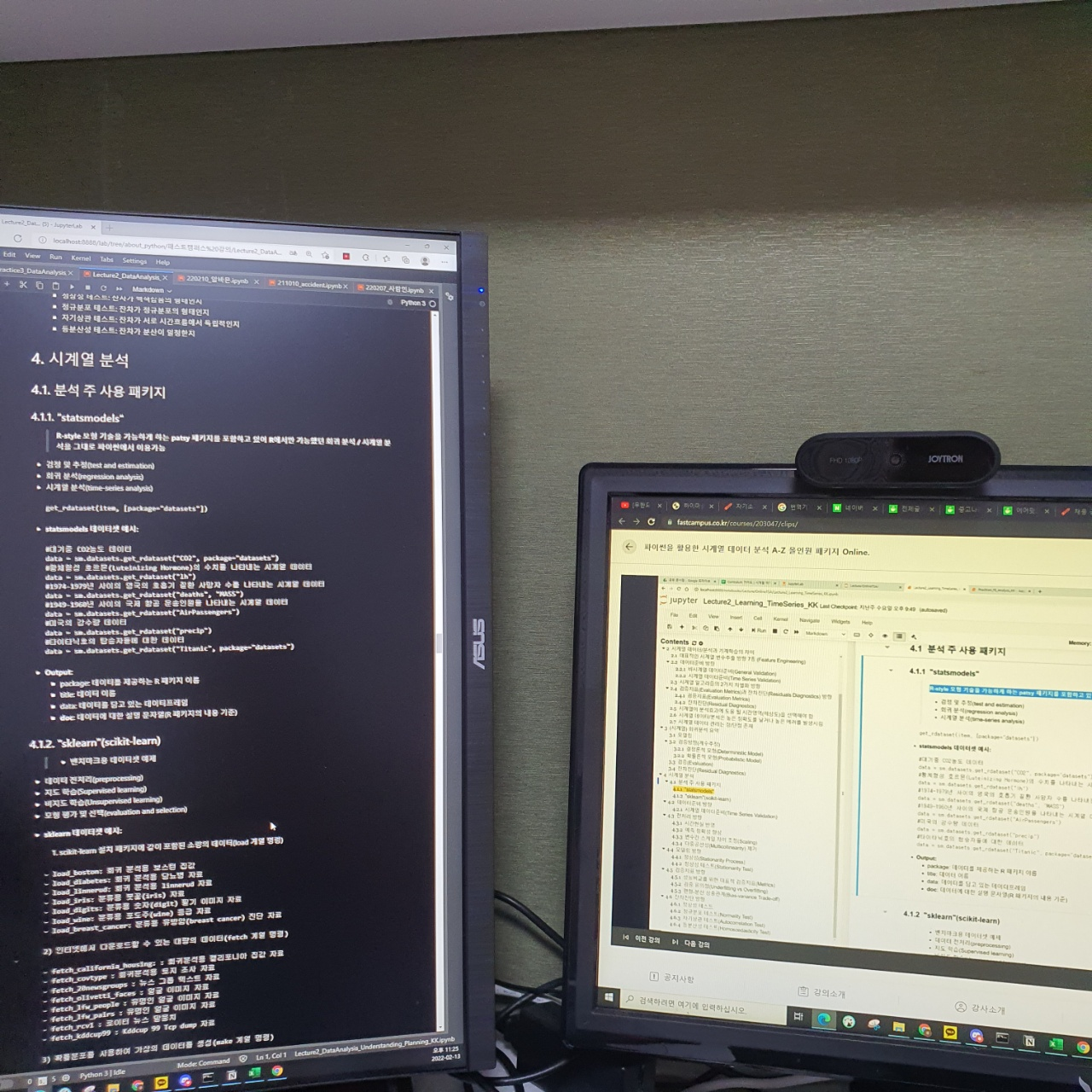
왼쪽화면은 강의자료화면이고 오른쪽은 강의화면이다.
이번 강의에서는 어떤 패키지를 이후에 사용할 것인지도 설명해주었다.
Sklearn, statsmodels 를 사용할 예정이다.
statsmodels 해당 패키지에서는 회귀분석과 여러 검증 및 통계 방법론을 사용할 수 있고 Sklearn은 학습에 더 특화된 패키지이다. 강화학습, 지도학습 등 다양한 학습에 필요한 기능들을 제공하는 패키지이다.
전처리 방향에서는 시간현실 반영을 해야한다고 했다.
무슨 말이냐면 기존에 모델을 학습 시킬 때 train과 test 데이터를 나눌 때 피처 엔지니어링을 다 하고 나누었다. 해당 test인 미래 시간에 대한 데이터를 모른다는 전제하에 진행해야하나 피처엔지니어링에 이를 알고 있다는게 포함되어 저번 강의에서 R square가 1이나오는 현상과 같은 맥락이다.
이런 상황들 때문에 시간현실 반영을 '제대로' 해야한다고 강의자는 말하고 있다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 23일차 (0) | 2022.02.15 |
|---|---|
| 패스트캠퍼스 챌린지 22일차 (0) | 2022.02.14 |
| 패스트캠퍼스 챌린지 20일차 (0) | 2022.02.12 |
| 패스트캠퍼스 챌린지 19일차 (0) | 2022.02.11 |
| 패스트캠퍼스 챌린지 18일차 (0) | 2022.02.10 |



