
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 클라우드
- 상관분석
- 딥러닝
- 리뷰
- nlp
- 데이터
- It
- 직장인자기계발
- 활성화함수
- 패스트캠퍼스후기
- 방콕여행
- 태국여행
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 직장인인강
- 챗지피티
- 자동매매프로그램
- 빅데이터
- 패스트캠퍼스
- 분석
- 머신러닝
- 패캠챌린지
- airflow
- Python
- 독서리뷰
- 파이썬
- DAGs
- Ai
- API
- ChatGPT
- 데이터분석
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 20일차 본문
오늘 강의는 1차 데이터 분석 준비의 마지막 강의 였다.
사실 강의 마지막에 강사님이 혹여나 1챕터에서 이해가 안가거나 조금은 혼란스러웠던 부분이 있으면 다시 돌아가 리마인드하고 다시 체크하라고 하셨지만 패스트 캠퍼스 50일 챌린지를 위해서 강의를 더 들으면서 이어나가야하는 부분이 조금 아쉬운 것 같다.
강의를 다 들은 것을 보여줘야하니...
서론은 이쯤에서하고 데이터 로드 부터 모델링 후 지표 산출과 검증까지 쭉 한 사이클을 돌리며 강의를 수강해왔다. 조금은 암울하지만 마지막 모델링 후 스케일링 전 모델과 스케일링 후 모델을 비교해보면 스케일링 전 모델은 유의한 변수들도 많고 잔차도 추세가 없이 좋아보였다. 하지만 스케일링이 되지 않아 정규성도 틀어지고 설명력도 낮은 모델이 된 것다.
스케일링을 진행 한 모델은 당연히 정규성을 보여지며 설명력이 1에 가까운 모델이 나왔다. 하지만 유의미한 독립변수는 적고 자기상관도 있어보이며 등분산도 시간이 갈 수록 커지는 것을 확인할 수 있었다.
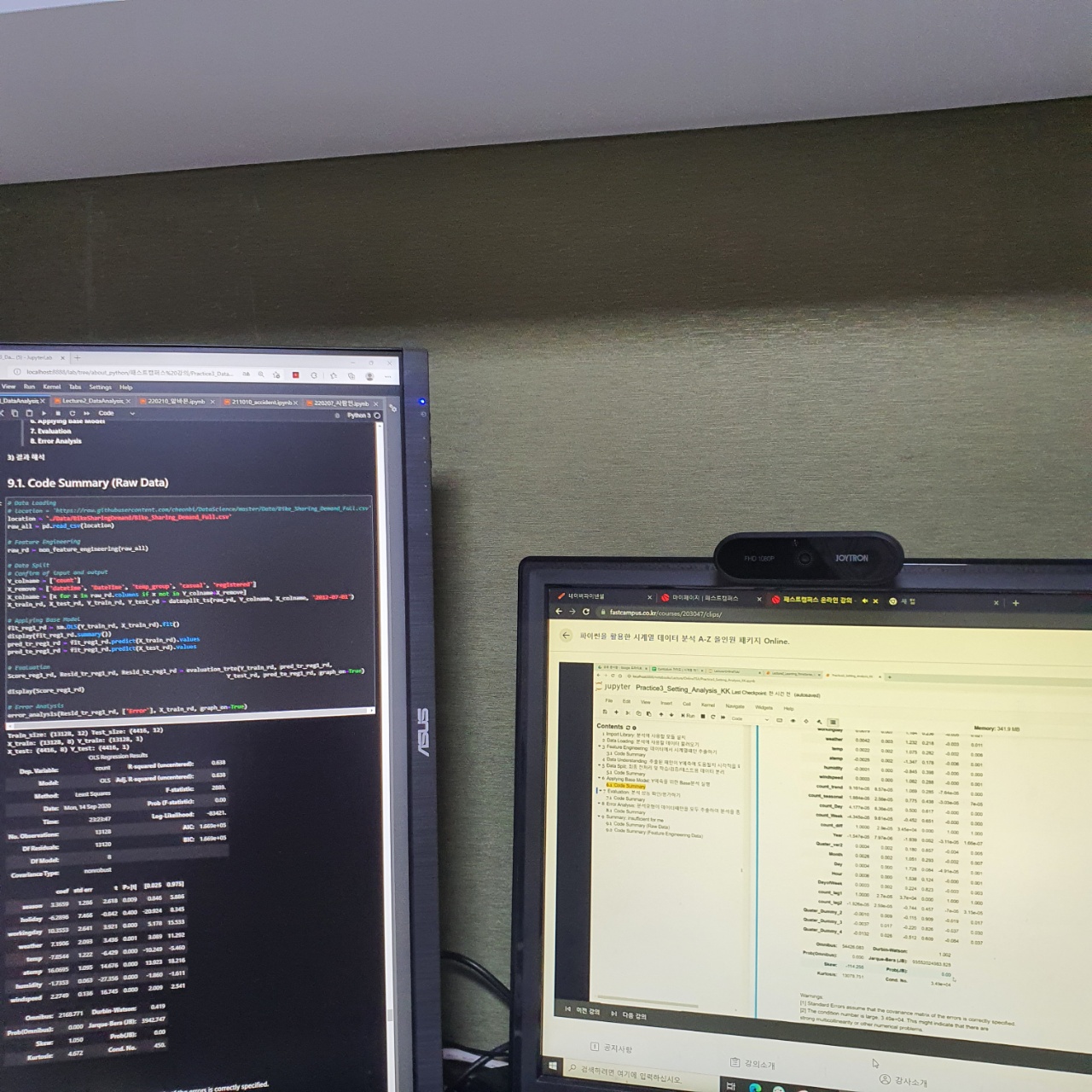
왼쪽 화면은 강의자료이고 오른쪽 화면은 강의화면이다.
해당 부분은 OLS를 통해 유의미한 독립변수들을 찾고 있는 과정이다.
P-value가 0.05 이하이면 해당 모델에 유의미한 변수라고 판단한다. 그리고 R square는 해당 모델에 대한 설명력이라 생각하면 된다.
스케일링 되기 전의 데이터로 모델을 돌린 것이라 유의미한 변수도 많지만 설명력이 상대적으로 낮은 것을 확인할 수 있다.
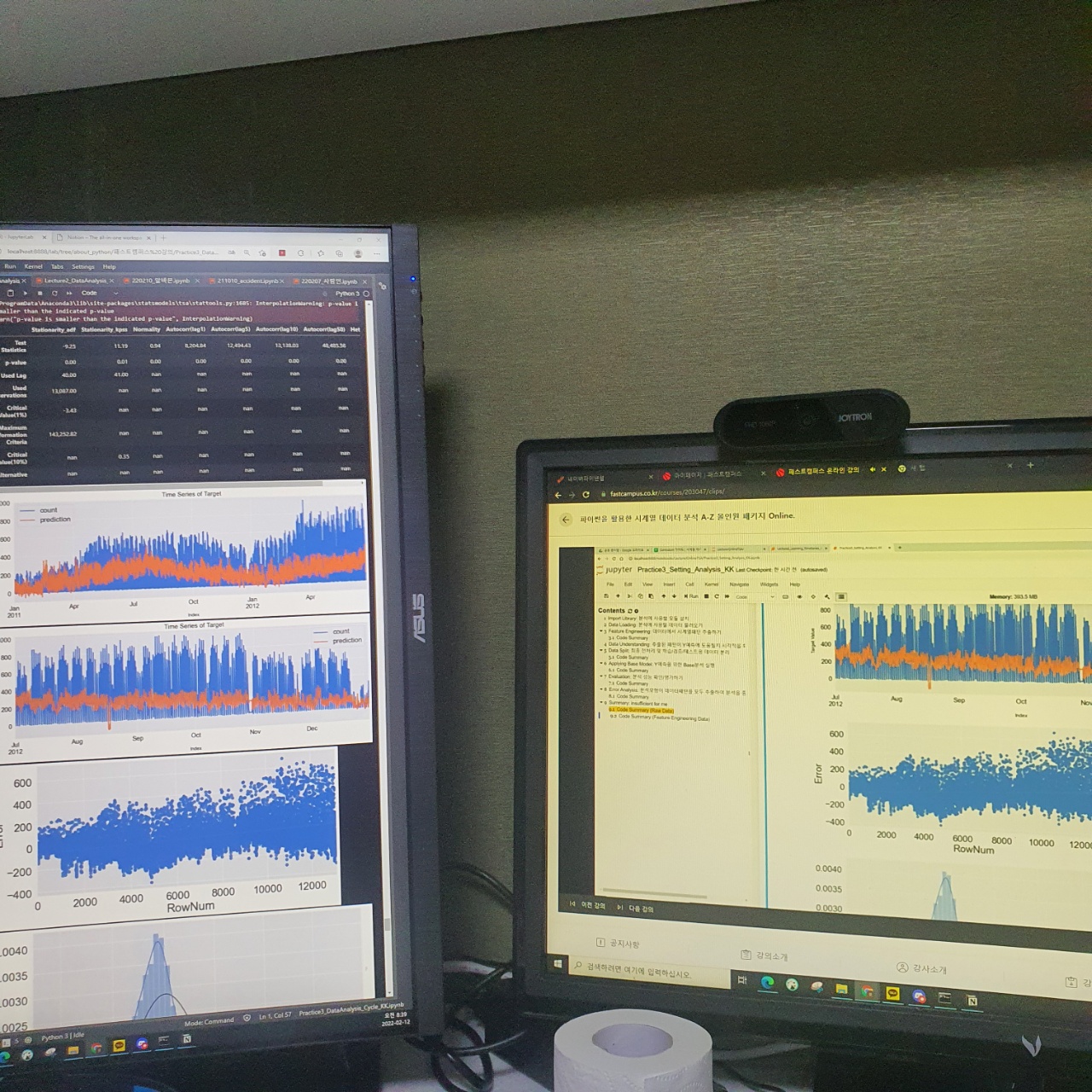
왼쪽 화면은 강의자료 화면이고 오른쪽 화면은 강의화면이다.
화면을 보면 정상성 / 자기상관 / 정규성 / 등분산성 을 시각화하여 체크하고 있는 부분이다. 아까 앞에서 말했듯이 스케일링이 안된 상태의 그래프들이다.
정규성을 확인하는 그래프를 보면 해당 데이터의 정규성을 그리고 해당 데이터의 그래프를 겹쳐서 보여준다. 그래프를 보면 어느 정도 정규성은 있는 것 같지만 그렇게 정규분포다 라고 말하기에는 조금 애매한 부분이 있는 것 같다.
강의 후 주말에 강의를 듣긴 하겠지만 추가로 챕터 1을 강의자료를 토대로 복습하는 시간을 가져야겠다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 22일차 (0) | 2022.02.14 |
|---|---|
| 패스트캠퍼스 챌린지 21일차 (0) | 2022.02.13 |
| 패스트캠퍼스 챌린지 19일차 (0) | 2022.02.11 |
| 패스트캠퍼스 챌린지 18일차 (0) | 2022.02.10 |
| 패스트캠퍼스 챌린지 17일차 (0) | 2022.02.09 |



