
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 빅데이터
- 직장인인강
- DAGs
- 파이썬
- 자동매매프로그램
- 데이터 분석
- 방콕여행
- API
- 패캠챌린지
- 분석
- 독서리뷰
- 패스트캠퍼스
- Python
- 에어플로
- 통계분석
- correlation
- 딥러닝
- airflow
- 태국여행
- 데이터분석
- 데이터
- 직장인자기계발
- EDA
- 머신러닝
- 상관분석
- 리뷰
- Ai
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 패스트캠퍼스후기
- 활성화함수
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 19일차 본문
어제에 이어서 실습 강의가 진행되었다.
이번에는 검증 통계량과 P-value 등을 추출하여 검증단계의 프로세스를 진행하는 실습 코드들을 설명해주는 강의었다.
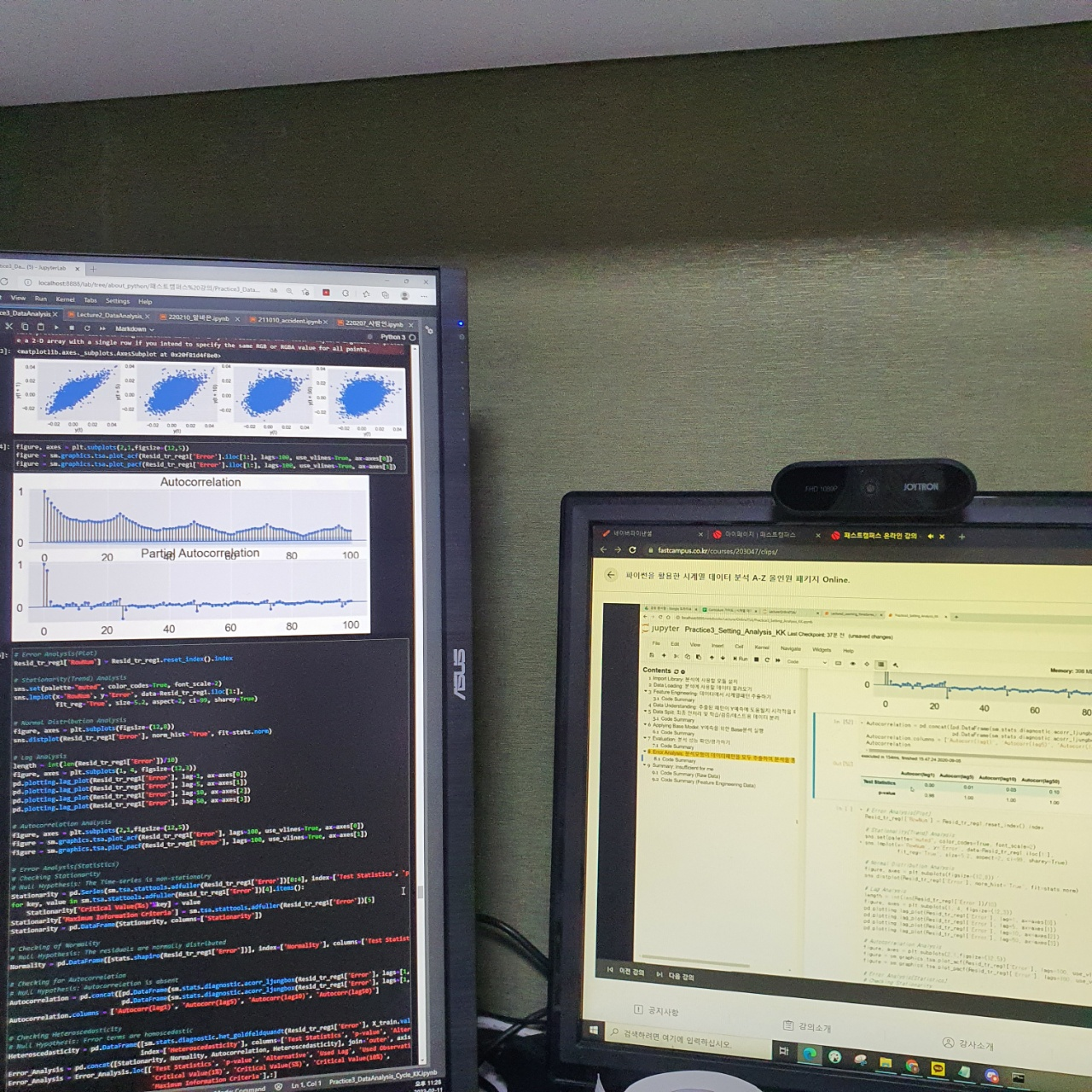
왼쪽은 강의자료화면이고 오른쪽은 강의화면이다.
화면을 보시면 왼쪽의 긴 코드들 하나하나를 설명해주었다. 정상성을 표현하는 부분 등분산성을 표현하는 부분 각각 코드에 반영되어 해당 부분을 수정해서 작업을 진행할 수 있도록 코드가 짜여져있었다.
각 통계량 마다 lag를 조절할 수 있고 함수처럼 변형하며 사용할 수 있도록 코드가 짜여져있어 이후 분석을 할 때 사용하기 편해보였다.
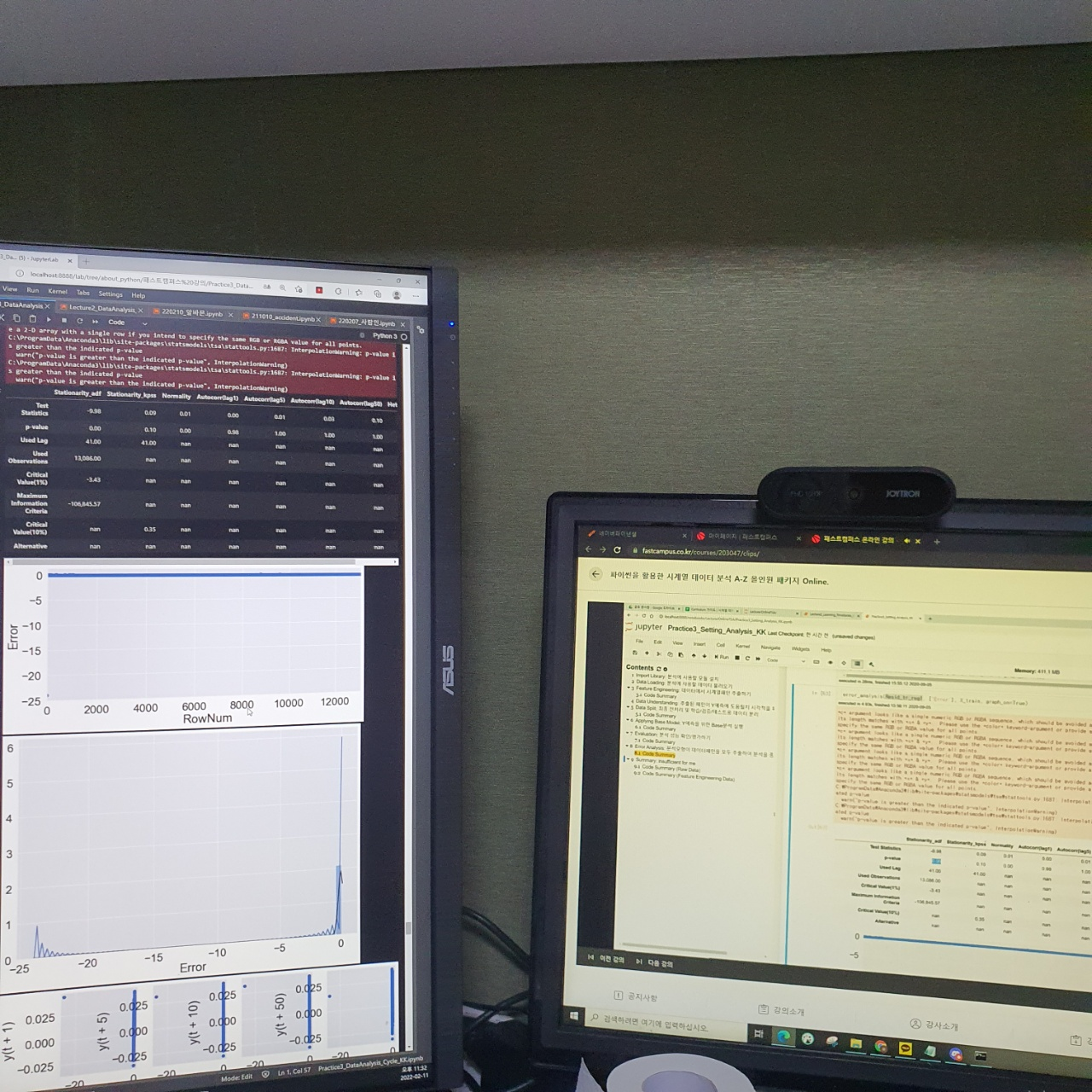
왼쪽은 강의자료화면이고 오른쪽은 강의화면이다.
왼쪽 화면을 보시면 해당 검정통계량 및 시각화를 통해 4가지의 검증을 나온 결과를 보고 각각의 기준 가설을 보며 통계량과 비교하며 검증을 진행한다.
그림을 보면 왼쪽 화면에는 정상성 / 정규성 / 등분산성 / 자기상관 4가지를 보여주는 시각화화면이 나온다.
앞서 강의들에서 설명해주었던 모든 시각화에 대한 작업들을 하나의 함수로 구현하여 볼 수 있도록 구축되어 있는 것이다.
이후 해석에서는 이전 강의에서 강조했던 백색잡음의 관점으로 그래프를 바라보는 작업을 진행하고 잔차 데이터를 보고 전처리를 진행하고 모델을 다시 수정하는 작업을 진행하게 된다.
왼쪽 화면을 보면 시각화를 하기 전에 데이터 스케일링 필요한 사례를 보여준다.
하나의 이상치 때문에 잔차에 대한 산점도가 한쪽으로 몰려나와 있는 것을 볼 수 있다. 이러한 스케일링 작업(이상치를 제거하거나 따로 스케일링을 하거나)을 함수에 반영하여 작업을 이어나갈 필요가 있어보인다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 21일차 (0) | 2022.02.13 |
|---|---|
| 패스트캠퍼스 챌린지 20일차 (0) | 2022.02.12 |
| 패스트캠퍼스 챌린지 18일차 (0) | 2022.02.10 |
| 패스트캠퍼스 챌린지 17일차 (0) | 2022.02.09 |
| 패스트캠퍼스 챌린지 16일차 (0) | 2022.02.08 |



