
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝
- 패스트캠퍼스후기
- 상관분석
- 머신러닝
- 패캠챌린지
- 리뷰
- 방콕여행
- 활성화함수
- 독서리뷰
- airflow
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 패스트캠퍼스
- 데이터
- Python
- 직장인인강
- DAGs
- nlp
- ChatGPT
- 태국여행
- 챗지피티
- 분석
- 데이터분석
- 자동매매프로그램
- 직장인자기계발
- API
- 클라우드
- Ai
- 빅데이터
- It
- 파이썬
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 23일차 본문
오늘 강의는 어제 중간까지 보다 이어지는 내용이다.
어제 시계열 데이터에 대한 전처리의 결과부분이다.
분기, 월 등 단순한 로직으로 값을 대체하여 모델링까지 진행을 해보면 설명력은 조금 떨어져도 데이터 자체의 유의미한 변수들이 많아졌다.
또한 이후 정상성, 자기상관 등 다양한 관점으로 확인을 해보니 Outlier도 없고 좀 더 정확도도 높은 현실적인 그래프들이 그려지는 것을 볼 수 있었다.
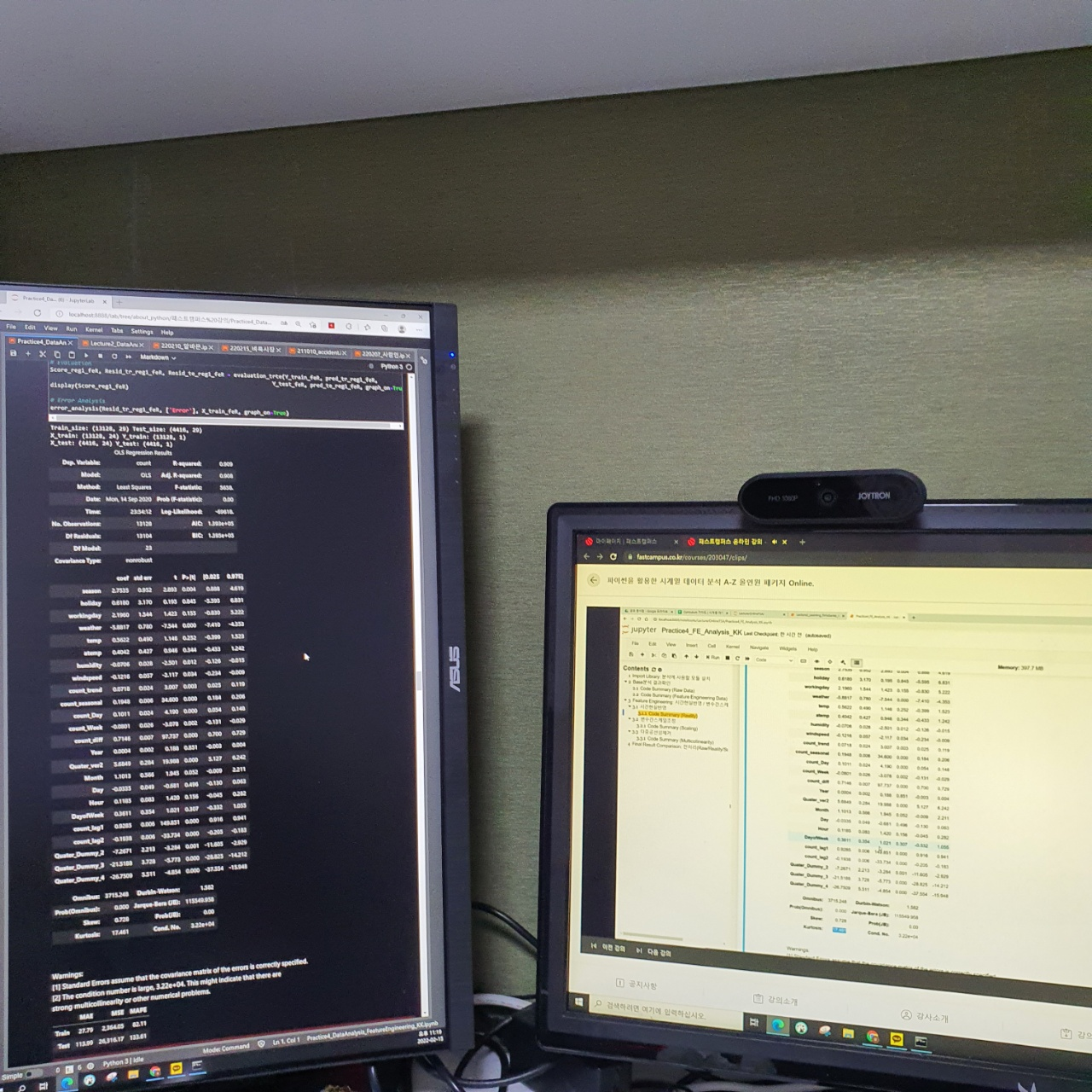
왼쪽화면은 강의자료 화면이고 오른쪽 화면은 강의 화면이다.
이어서 오늘의 새로운 강의는 Condition Number에 관련된 강의로 시작되었다.
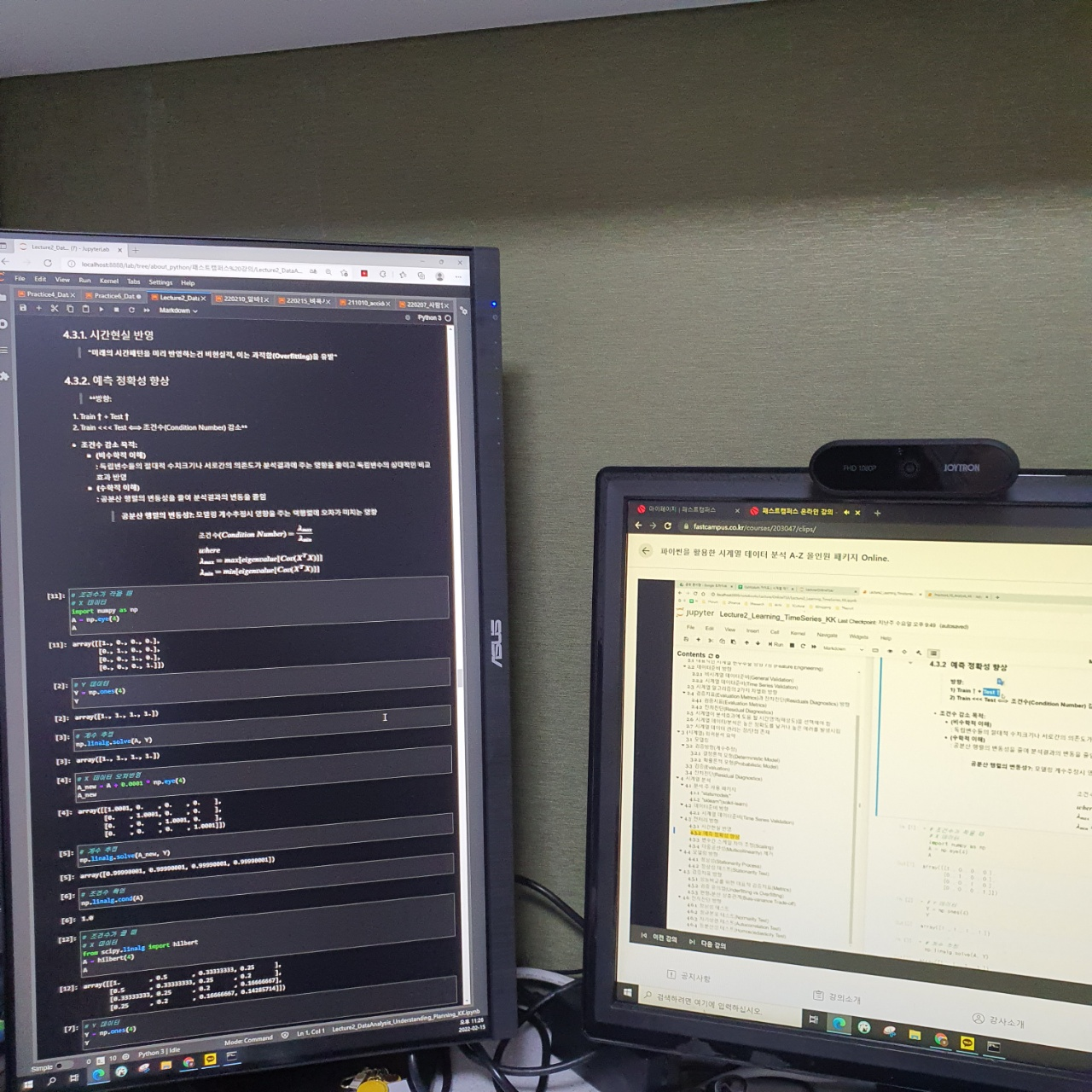
왼쪽화면은 강의자료 화면이고 오른쪽 화면은 강의 화면이다.
train과 test의 성능을 향상시켜야하지만 이를 같이 향상하는게 목표이지만 두 개다 동시에 성능을 향상시키기에는 어렵다고 예전 강의에서 설명을 해주셨다.
그래서 우리는 train보다는 test의 성능이 향상되는 것을 목표로 하면 좋을 것이라 말하는데 이유는 과거에 대한 현상에 관점이 치우쳐있다 한들 미래에 대한 데이터의 현상을 설명이 가능해야 과거도 잘 설명한 것이라 볼 수 있다.
이런 방향으로 가려면 Condition Number(조건수)를 감소시켜야한다.
Condition Number(조건수) = X에 대한 특징을 기반으로 추출하는 것인데 이러한 조건수가 감소할 수록
조건수 감소의 목적이 비수학적 이해는 독립변수들의 절대적 수치크기나 서로간의 의존도가 분석결과에 주는 영향을 줄이고 독립변수의 상대적인 비교효과를 반영하는 것이라 한다.
강의자님께서는 tv광고와 영화관 광고를 예시를 들어주었다.
둘 다 사람의 관점으로는 독립적으로 보여지나 컴퓨터의 관점에서는 각각 독립적이지 않게 노출된다고 생각할 수 있다.
또한 x1 컬럼과 x2의 컬럼이 전혀 관계가 없음에도 불구하고 어떠한 규칙에 의해 생성되는 것이 보여지거나 상관계수가 높다면 각 변수에 대한 패턴을 모델이 더 많이 학습을 하게됨으로 이러한 것을 제거(감소)해야 더 좋은 모델을 구축할 수 있다는 것이다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 25일차 (0) | 2022.02.17 |
|---|---|
| 패스트캠퍼스 챌린지 24일차 (0) | 2022.02.16 |
| 패스트캠퍼스 챌린지 22일차 (0) | 2022.02.14 |
| 패스트캠퍼스 챌린지 21일차 (0) | 2022.02.13 |
| 패스트캠퍼스 챌린지 20일차 (0) | 2022.02.12 |



