
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 패스트캠퍼스
- 딥러닝
- 리뷰
- correlation
- 빅데이터
- 파이썬
- 패스트캠퍼스후기
- Ai
- DAGs
- 데이터 분석
- 패캠챌린지
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 태국여행
- 머신러닝
- 직장인인강
- 직장인자기계발
- Python
- 데이터
- API
- airflow
- 활성화함수
- EDA
- 자동매매프로그램
- 에어플로
- 데이터분석
- 통계분석
- 방콕여행
- 분석
- 독서리뷰
- 상관분석
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 4일차 본문
이번 강의는 'ch02.데이터분석 준비하기 시계열 분석 알고리즘 이해' 였다.
기본적인 머신러닝에 대한 설명을 시작으로 강의가 시작되었다.
머신러닝은 크게 Superviesd Learning과 Unsuperviesd Learning 으로 나뉜다.
한마디로 결과값이 있는 것과 결과값이 없는 것의 차이인데 이를 더 쉽게 표현하자면 Superviesd Learning은 지도학습으로 해당 모델이 어떤 걸 예측해야하는지 값을 주어진다. 그 이후 미래에 들어오는 데이터들의 대한 예측을 진행하는 것이다.
반대로 Unsuperviesd Learning은 예측해야하는 결과값이 주어지지 않은 상태에서 해당 결과값을 예측해야한다고 이해하면 편하다. 예를 들어 비지도학습의 대표적인 군집분석으로 예를 들어보자.
기존에 고객을 멤버쉽 개념으로 분류작업을 하고자 한다. 이럴 때 몇가지의 그룹을 나눌지 사전에 선택한 고객들의 데이터를 기반으로 유사한 성격을 띄고 있는 그룹으로 분류를 한다. 이러한 작업을 Unsuperviesd Learning 이라고 한다.
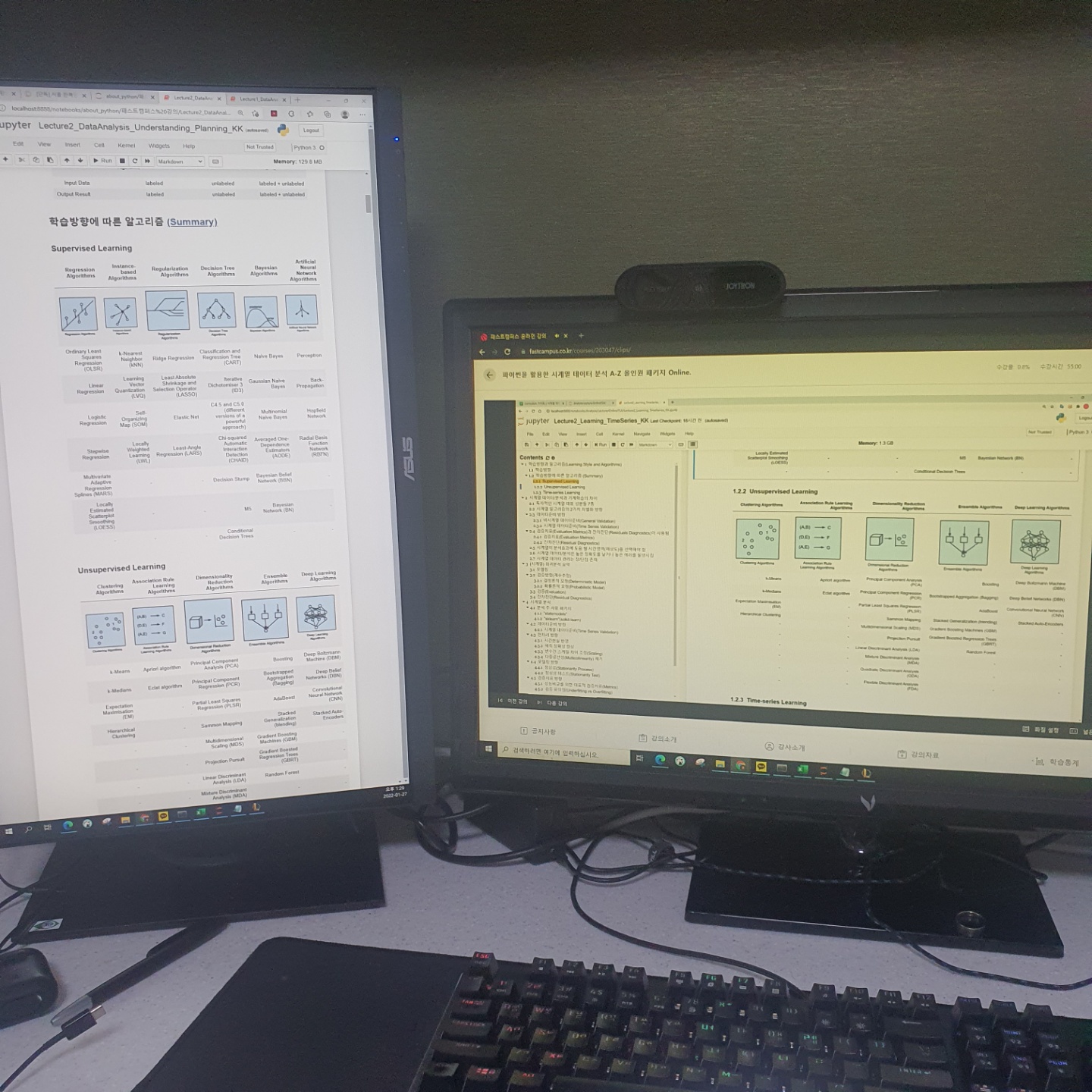
왼쪽 화면은 강의 자료이고 오른쪽은 강의화면이다.
보이는 것처럼 강의자료에 Superviesd Learning과 Unsuperviesd Learning 의 분포 이미지와 해당 모델 별 정리를 깔끔하게 해주셔서 이해가 쉬웠다.
그리고 이후에는 정확도와 설명력에 대한 강의가 이어졌다.
두 수치는 반비례관계가 있다고 설명을 해주셨다.
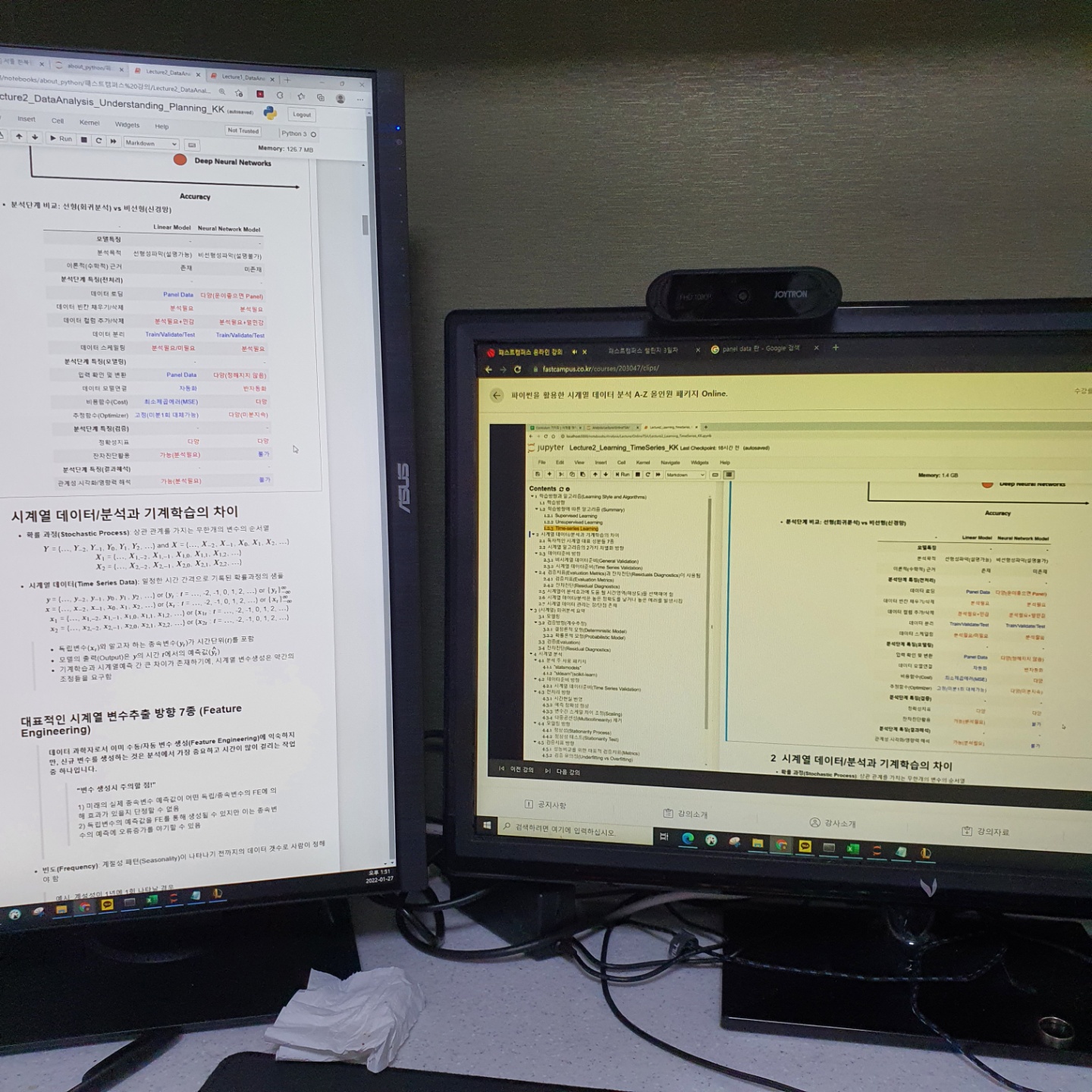
왼쪽 화면은 강의 자료이고 오른쪽은 강의화면이다.
처음에는 반비례 관계에 대한 이해가 안됐지만 설명을 들으니 이해가 갔다.
Linear model 에 같은 경우 통계적인 가설들을 기반으로 구간추청을 진행하기에 해당 변수별 중요도 및 설명이 가능한데 딥러닝과 같은 모델들은 예측에 중점을 맞춰 컴퓨터가 연산하여 예측을 진행하기에 각 변수마다 그리고 모델에 대한 설명력 자체가 낮다고 한다.
주가 예측에 대해서는 설명력보다는 정확도가 더 비중이 있는 식으로 접근해야될 것 같다는 생각이 들었다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 6일차 (0) | 2022.01.29 |
|---|---|
| 패스트캠퍼스 챌린지 5일차 (0) | 2022.01.28 |
| 패스트캠퍼스 챌린지 3일차 (0) | 2022.01.26 |
| 패스트캠퍼스 챌린지 2일차 (0) | 2022.01.25 |
| 패스트캠퍼스 챌린지 1일차 (0) | 2022.01.24 |



