
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 빅데이터
- 파이썬
- ChatGPT
- Python
- 직장인자기계발
- 데이터분석
- nlp
- 딥러닝
- 패캠챌린지
- It
- 패스트캠퍼스후기
- 데이터
- 분석
- 패스트캠퍼스
- 활성화함수
- 태국여행
- DAGs
- 직장인인강
- airflow
- API
- 클라우드
- 머신러닝
- 리뷰
- 독서리뷰
- Ai
- 챗지피티
- 자동매매프로그램
- 상관분석
- 방콕여행
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 6일차 본문
오늘의 강의는 어제의 챕터가 이어지는 중이다.
이번에는 시계열 데이터의 전처리 과정을 좀 더 세부적으로 보여주는 강의었다.
일반적인 수치형 데이터를 예측하기 위한 머신러닝 모델을 구축할 때도 feature engineering을 진행할 때 범주형변수로 만들어 주기 위해 원핫인코딩을 진행하는 경우가 있다.
오로지 수치형 데이터만 존재하는 것이 아닌 범주형 데이터가 존재할 때 해당 데이터를 컴퓨터가 인식할 수 있도록 각 클래스 별로 0,1 로 구분하여 컬럼을 새로 생성하는 것이 더미변수화 하는 작업이다.
해당 부분의 피처 엔지니어링 방식이 시계열에도 동일하게 적용될 줄은 몰랐다.
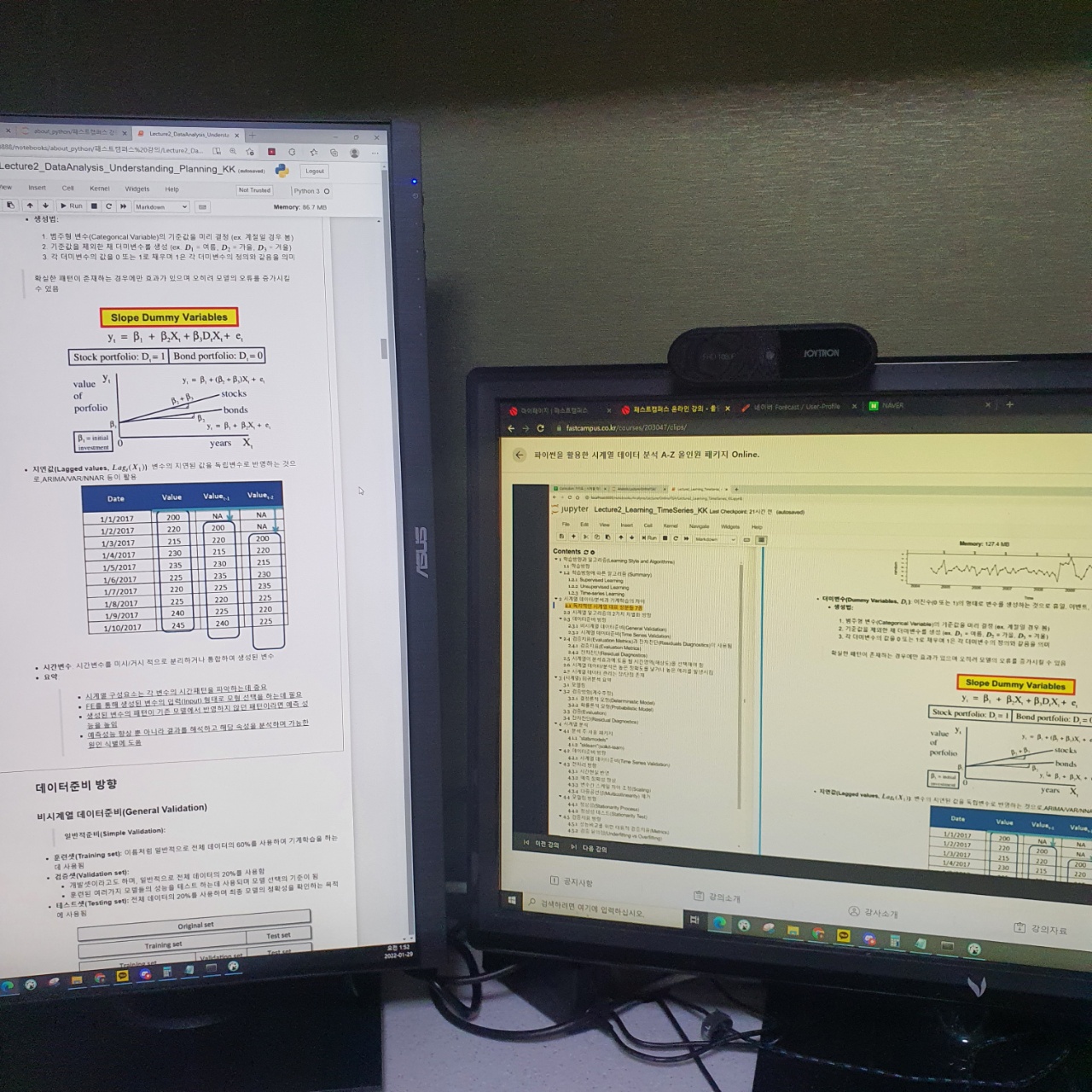
왼쪽화면은 강의자료이고 오른쪽화면은 해당 강의화면이다.
강의화면에 보듯이 수식에 인자들이 많다. 해당 인자들은 더미변수를 통해 변수를 나눈 후 반영된 수식이다.
이렇게 변수 타입을 성격에 맞게 엔지니어링을 다 한 후 시계열 데이터이다 보니 특정 시점 이후 효과를 보여지는 데이터의 특성이 있을 때가 있다.
강의에서는 광고로 예시를 들어주었다.
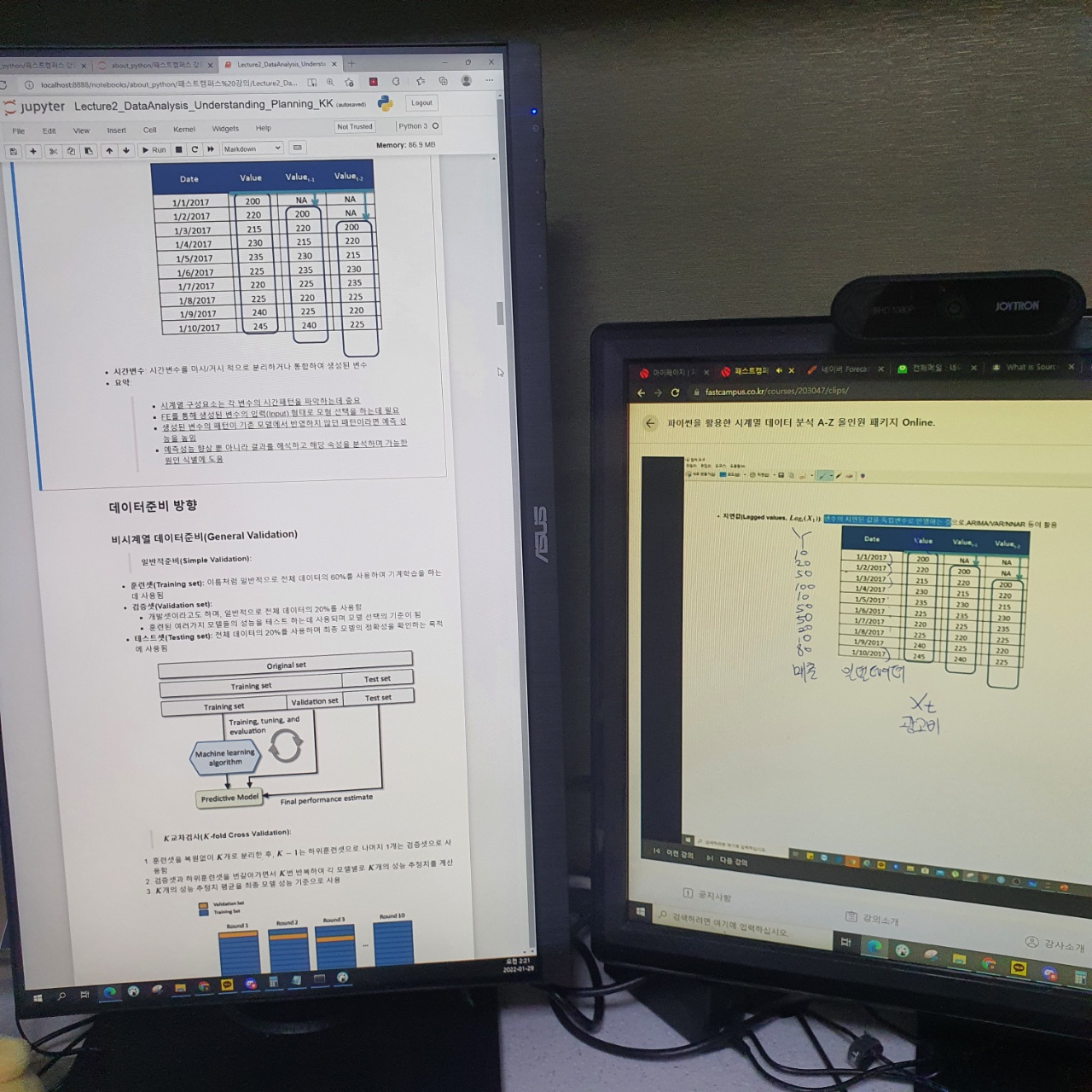
왼쪽화면은 강의자료이고 오른쪽화면은 해당 강의화면이다.
오른쪽 화면을 보면 광고비가 특정시점에 들어가고 그 이후 다음날 부터 광고가 진행되니 이전과 비교하며 보고자하여 시점 1개를 늦춰서 컬럼을 생성하는 것을 지연값(Lagged values) 라고 한다.
해당 값은 ARIMA 나 MA 등 다양한 시계열 분석에서 쓰인다고 한다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 8일차 (0) | 2022.01.31 |
|---|---|
| 패스트캠퍼스 챌린지 7일차 (0) | 2022.01.30 |
| 패스트캠퍼스 챌린지 5일차 (0) | 2022.01.28 |
| 패스트캠퍼스 챌린지 4일차 (0) | 2022.01.27 |
| 패스트캠퍼스 챌린지 3일차 (0) | 2022.01.26 |



