
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 리뷰
- API
- correlation
- EDA
- 머신러닝
- 직장인인강
- 데이터
- airflow
- 에어플로
- 자동매매프로그램
- 빅데이터
- 패캠챌린지
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 데이터분석
- 딥러닝
- Ai
- 직장인자기계발
- 패스트캠퍼스후기
- 파이썬
- 상관분석
- DAGs
- 독서리뷰
- Python
- 태국여행
- 데이터 분석
- 방콕여행
- 통계분석
- 활성화함수
- 분석
- 패스트캠퍼스
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 30일차 본문
오늘 강의는 정상성 통계량 확인과 정상성 테스트 실습을 진행했다.
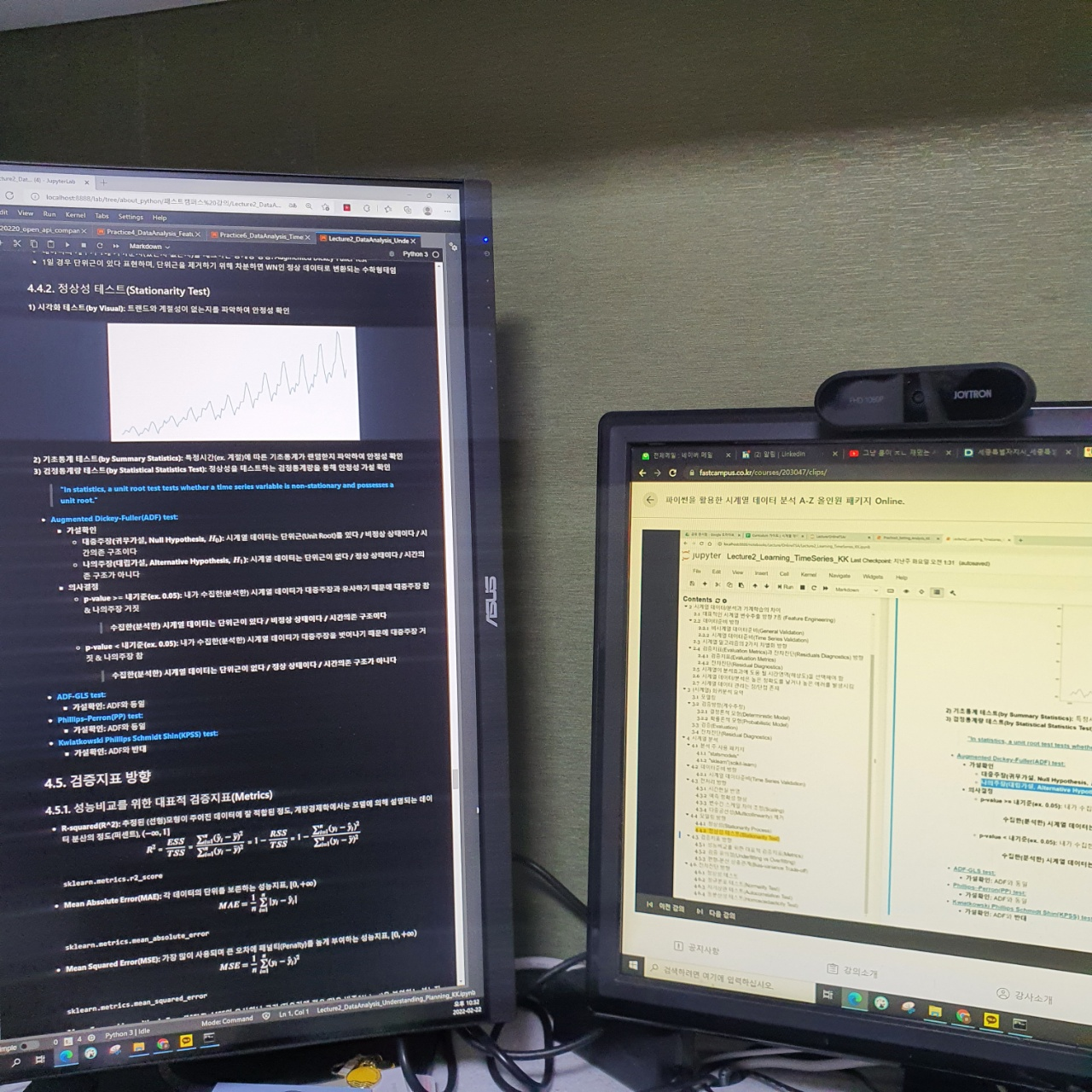
왼쪽은 강의자료 화면이고 오른쪽은 강의화면이다.
정상성 테스트 부분을 보면 어디선가 본적이 있는 느낌이 들었다. 아니나 다를까 강의에서 강사님도 동일한 표현을 하시며 물어보았다.
바로 잔차 검정에서 본 부분과 동일했다. 해당 검증 방법이나 원리도 동일했다.
해당 테스트를 하는 방법은 크게 3가지가 있다. 시각화 테스트 / 기초통계 테스트 / 검정통계량 테스트 이다.
시각화 테스트란 왼쪽 화면에서도 보이듯이 그래프를 직접 그려보며 육안으로 확인하는 것을 의미한다.
기초통계 테스트는 특정시간에 따른 기초통계가 랜덤한지 파악하여 안정성을 확인 하는 것이다.
마지막으로 검정 통계량 테스트는 가설 검정의 단계라고 보면 된다.
정상성 테스트에서 귀무가설은 시계열 데이터는 비정상 상태이다 / 대립가설은 시계열 데이터는 정상 상태이다.
이렇게 구분되어 가설 검정을 진행한다.
잔차와 Yt(종속변수)가 정상성을 만족해야한다. 만약 종속변수가 정상성을 만족하지 못하면 파라미터 추정이 불가하다.(시계열 알고리즘에서)
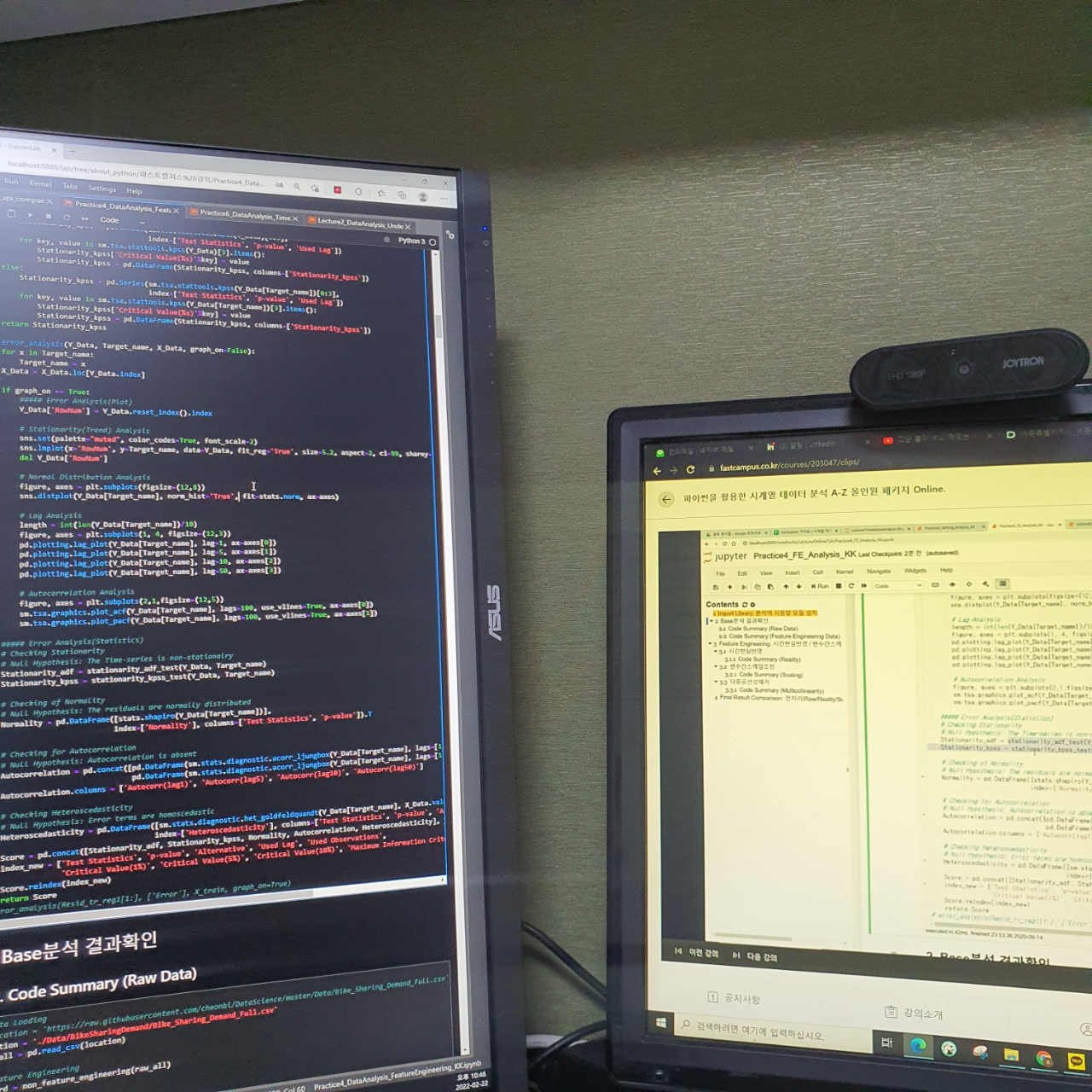
왼쪽은 강의 실습 코드 화면이고 오른쪽은 강의화면이다.
실습 코드 중 stationary_adf_test / stationary_kpss_test 라는 함수를 사용하면 검정통계량과 p-value 등 가설 검증에 대한 값들이 도출된다.
p-value가 유의수준보다 작으면 대립가설을 채택한다 고로 비정상이라고 해석할 수 있다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 32일차 (0) | 2022.02.24 |
|---|---|
| 패스트캠퍼스 챌린지 31일차 (0) | 2022.02.23 |
| 패스트캠퍼스 챌린지 29일차 (0) | 2022.02.21 |
| 패스트캠퍼스 챌린지 28일차 (0) | 2022.02.20 |
| 패스트캠퍼스 챌린지 27일차 (0) | 2022.02.19 |



