
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Ai
- 데이터분석
- 패스트캠퍼스후기
- 에어플로
- 딥러닝
- 직장인자기계발
- API
- 빅데이터
- EDA
- airflow
- 데이터 분석
- 패스트캠퍼스
- 독서리뷰
- 데이터
- 패캠챌린지
- correlation
- Python
- 자동매매프로그램
- 활성화함수
- 머신러닝
- 방콕여행
- 직장인인강
- 분석
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 통계분석
- 리뷰
- 상관분석
- 태국여행
- DAGs
- 파이썬
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 29일차 본문
이번 강의는 저번 강의에 이어서 비정상성 데이터를 정상성으로 변환하여 예측 후 비정상성으로 다시 바꾸는 과정에 대한 설명으로 시작되었다.
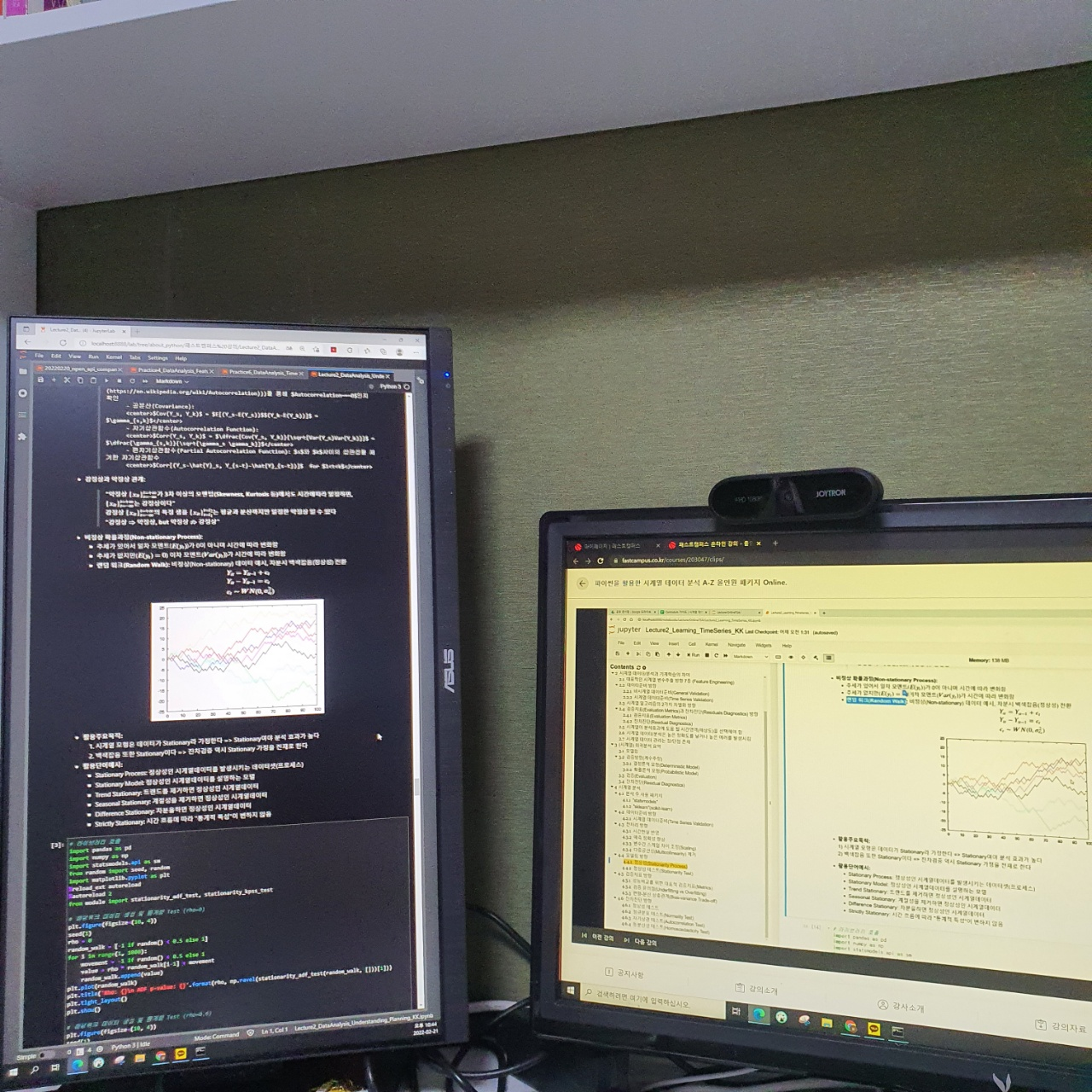
왼쪽 화면은 강의 자료이고 오른쪽 화면은 강의 화면이다.
정상성의 대표 알고리즘은 백색소음이라 했고 비정상 프로세스를 대표하는 것은 랜덤 워크(Random Walk)라는 알고리즘이라 한다.
랜덤 워크는 랜덤하게 어떤 방향으로 이동할지 모르는 것을 랜덤워크라고 한다. 왼쪽 화면의 예제 그래프를 보면 어디로 갈지 방향성이 난해한 것들을 확인할 수 있다.
차분은 바로 이전 시점과 현재시점의 차이를 말한다.
차분은 Yt의 증가량이라고 본다. 차분은 보통 특정 범위에서 일정하게 나온다.
이렇게 차분을 한 값이 정상성을 따르고 그 이후 다시 비정상성으로 변환하려면 누적합을 진행해준다.
다시 한마디로 정리하면 비정상성(랜덤워크)를 정상성으로 바꾸기 위해 차분을 하고 이때 차분한 값은 정상성을 띄는 백색 잡음이며 다시 비정상성으로 변환하기 위해 누적합을 이용해 준다는 것이다.
활용 주요 목적에서 Stationary를 가정해야 분석효 과가 높다고 한다.
해당 이유는 예측효과가 높아지고 파라미터가 적어져 알고리즘이 단순해진다.
(→ 너무 과적합 되는 것을 방지한다라고 해석하는 것이 더 정확하다)
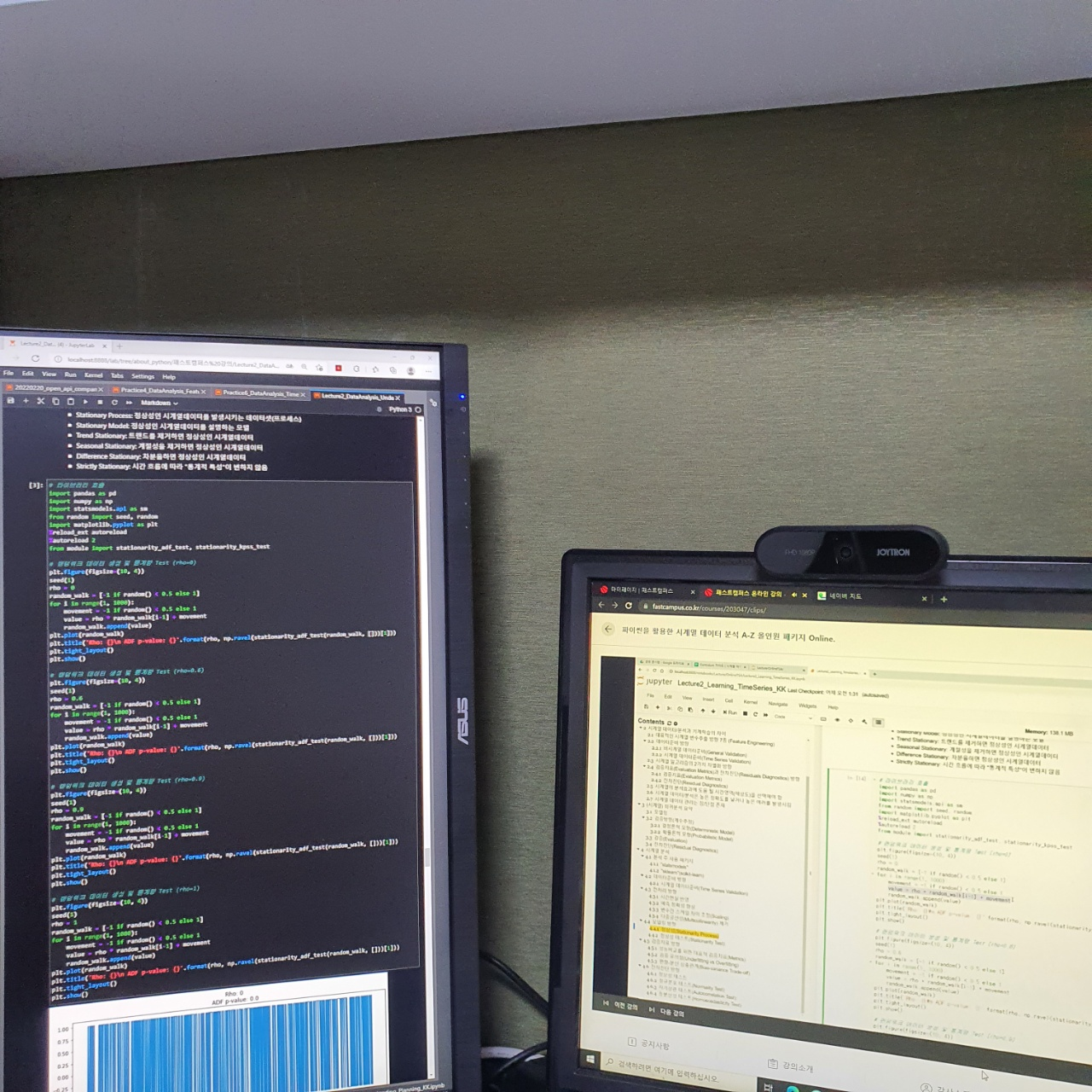
왼쪽 화면은 강의 자료이고 오른쪽 화면은 강의 화면이다.
이후 지금까지 설명했던 것을 실습코드로 구현한 화면이 왼쪽 강의 자료 화면이다.
코드들은 계수를 0.1 ~ 1까지 조절하며 그래프를 보여주었다. 1인 계수는 즉 랜덤워크에 대한 내용이었다.
수식은 value = 계수 * t-1 시점의 랜덤워크 + 백색잡음(잔차) 에서 계수를 조절하며 보는 것이었다.
계수가 1에 가까울 수록 비정상에 가까워진다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 31일차 (0) | 2022.02.23 |
|---|---|
| 패스트캠퍼스 챌린지 30일차 (0) | 2022.02.22 |
| 패스트캠퍼스 챌린지 28일차 (0) | 2022.02.20 |
| 패스트캠퍼스 챌린지 27일차 (0) | 2022.02.19 |
| 패스트캠퍼스 챌린지 26일차 (0) | 2022.02.18 |



