
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 독서리뷰
- 파이썬
- 데이터
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 빅데이터
- 분석
- DAGs
- Python
- EDA
- 패캠챌린지
- airflow
- 머신러닝
- 직장인인강
- 데이터 분석
- Ai
- 자동매매프로그램
- 직장인자기계발
- correlation
- 태국여행
- 활성화함수
- API
- 딥러닝
- 패스트캠퍼스후기
- 에어플로
- 통계분석
- 패스트캠퍼스
- 상관분석
- 데이터분석
- 방콕여행
- 리뷰
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 9일차 본문
오늘의 강의는 어제에 이어서 실습으로 진행되었다.
오늘도 본가여서 누나의 mac 으로 인강을 들으며 테블릿을 통해 자취장 pc에 원격으로 붙여 코딩을 진행하였다.
어제까지의 실습 코드에 대한 내용은 결측치처리에 관한 내용이었다.
시계열 데이터의 결측치 처리에서 datetime의 구간이 시간, 일자, 월별 등 다양한 기준으로 구성할 수 있으며 각 기준별로 결측치가 상이할 수도 있다.
그렇게 결측치에 대한 처리를 완료한 뒤 데이터의 특성을 확인해보고자 시계열 데이터의 EDA를 진행하였다.
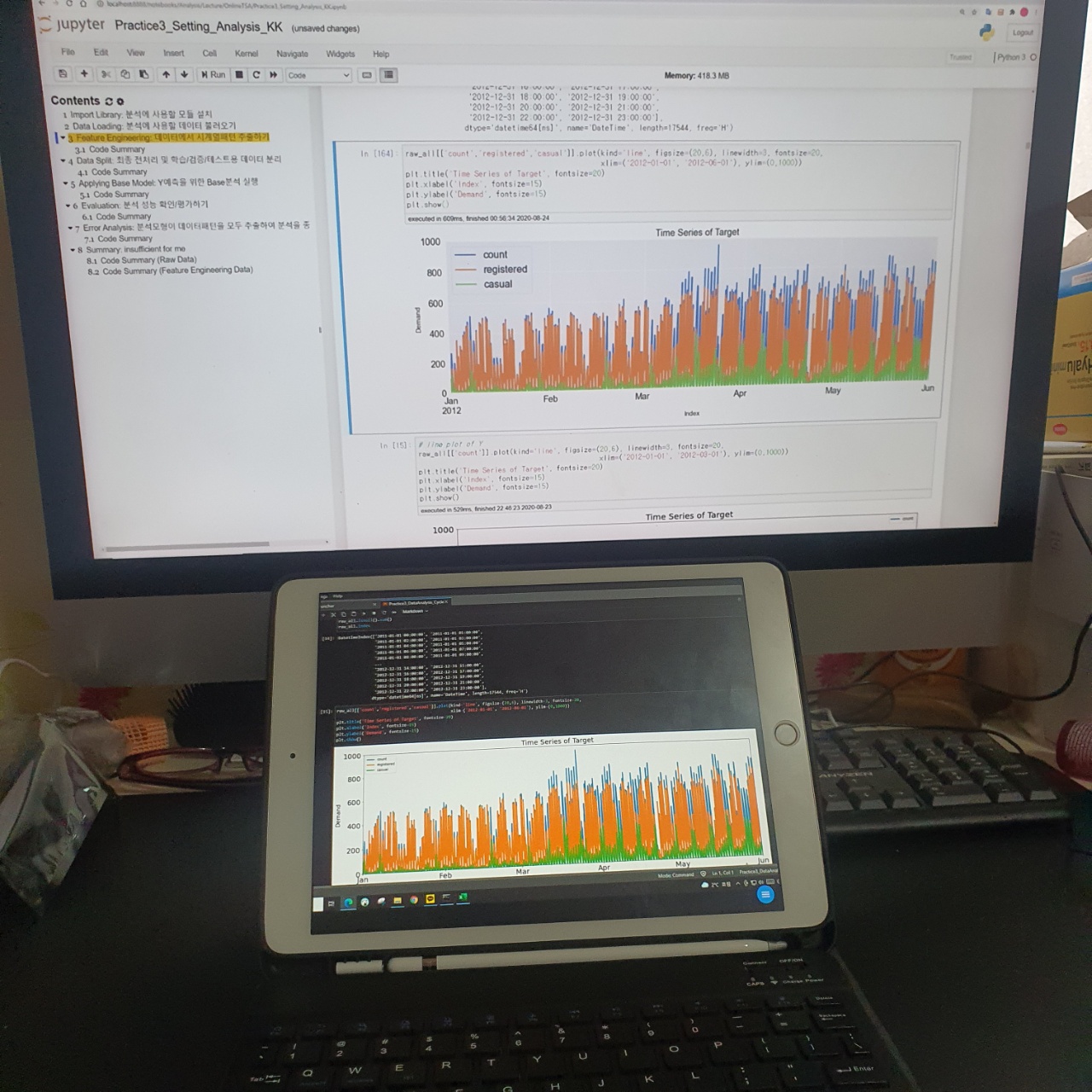
위의 mac은 강의화면이고 테블릿 코딩 화면이다.
가장 먼저 진행했던 것은 일별 카운팅과 registered / casual 으로 그래프를 겹쳐 그리면서 확인을 하는 것으로 시작되었다.
처음은 일별 카운팅으로만 시간별 흐름상 언제 수치가 많고 적은지 한눈에 볼 수 있는 그래프를 그렸다.
이후 각 특성별로 그래프를 따로 보기보단 한번에 겹쳐 보고자 그래프 자체를 겹쳐 그리면서 데이터 특성에 대한 이해를 한 스텝 더 깊이 할 수 있었다.
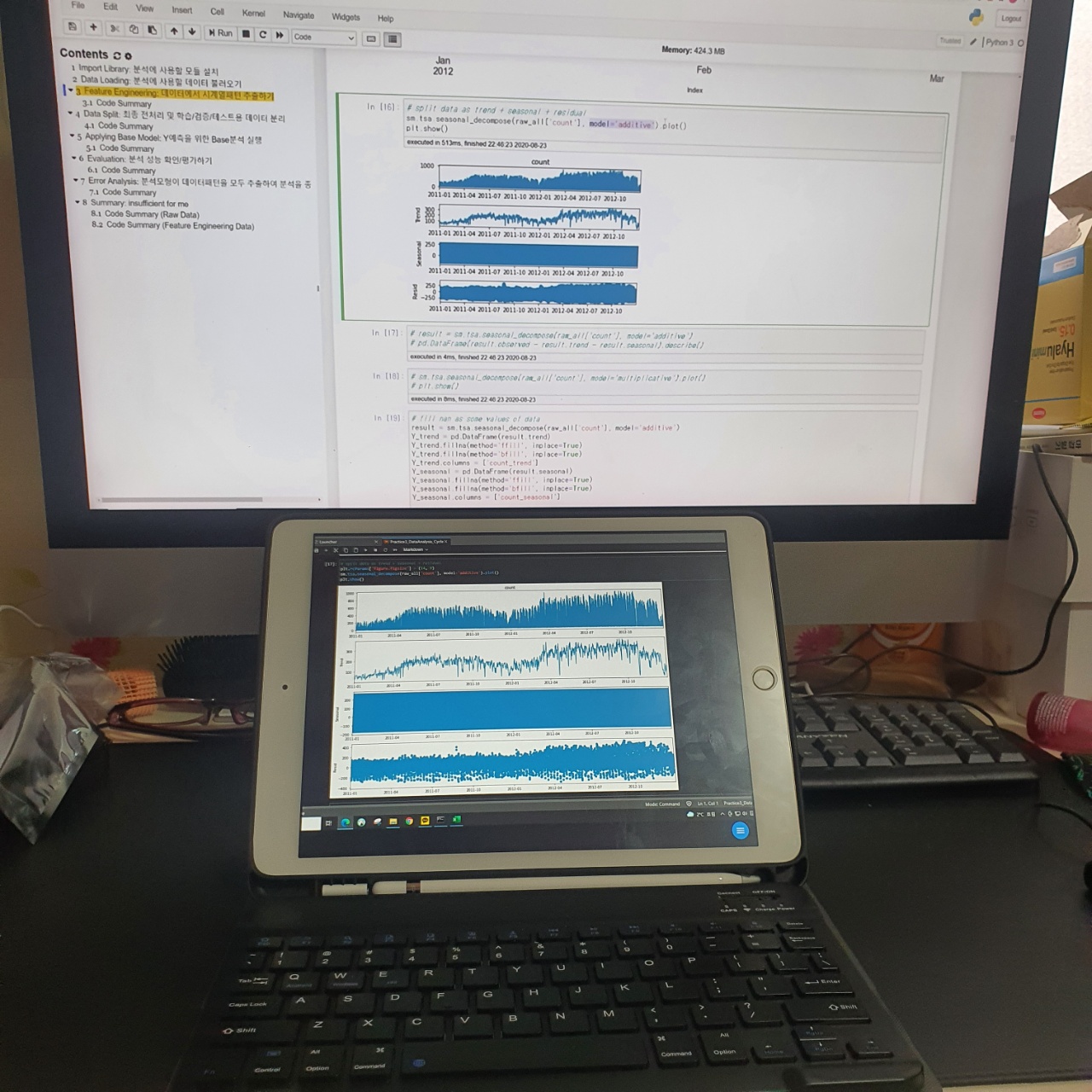
위 쪽 mac화면은 강의화면이고 아래 테블릿 화면은 코딩화면이다.
이전 이론시간에 배웠던 시계열 변수에 대한 4가지 trend / seasonal / resid / count 가 기억이 났다.
해당 관련 이론이 처음엔 명확하게 생각나지 않아 이전에 블로그에 작성했던 글을 참고하여 다시 리마인드하는 시간을 가졌다.
4가지 그래프를 한번에 추출하여 해당 데이터의 특성을 관찰해보았다.
단순한 count그래프를 보면 시간이 지날 수록 수요가 올라가는 것을 확인할 수 있다. 좀 더 상세하게 보면 계절별로 수요의 차이가 조금씩 나타나기 시작한다.
사진에는 보이지 않지만 seasonal 에 range가 0~2 와 0~250 으로 나뉜 코드들이 존재했다.
(옵션값에 의해 바뀌는 것)
해당 값에서는 육안으로 보고 데이터의 도메인이나 성격을 이해한 상태에서 옵션값을 선택해야한다고 하셨다.
수치 자체가 0~2 는 말이 안되는 수치였고(단순 count그래프의 range를 보면 감이온다) 0~250의 옵션값을 선택하여 추후 분석에 이용할 것이라고 하였다.
추가로 그래프를 그릴때 matplotlib의 그래프를 겹쳐 그릴 때 마지막에 plt.show()를 진행하지 않으면 그래프가 겹치게 안나오는 것을 알게되었다.
시각화에 대한 다양한 기능들이 존재하지만 아직 많이 섭렵하지 못한 것 같다. 추가적인 matplotlib에 대한 공부가 필요하다고 생각되었다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 11일차 (0) | 2022.02.03 |
|---|---|
| 패스트캠퍼스 챌린지 10일차 (0) | 2022.02.02 |
| 패스트캠퍼스 챌린지 8일차 (0) | 2022.01.31 |
| 패스트캠퍼스 챌린지 7일차 (0) | 2022.01.30 |
| 패스트캠퍼스 챌린지 6일차 (0) | 2022.01.29 |



