
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 리뷰
- airflow
- 활성화함수
- 패스트캠퍼스
- 빅데이터
- 태국여행
- 독서리뷰
- DAGs
- 직장인자기계발
- 딥러닝
- 패캠챌린지
- 자동매매프로그램
- 직장인인강
- 에어플로
- 통계분석
- correlation
- Python
- Ai
- 데이터 분석
- EDA
- 머신러닝
- 데이터분석
- 방콕여행
- 상관분석
- API
- 분석
- 파이썬
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 패스트캠퍼스후기
- 데이터
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 최종 후기 본문
드디어 마지막 후기를 올리는 날이 왔다.
누군가에겐 50일이 짧으면 짧고 길면 긴 기간이지만 직장인에게 퇴근 후 1시간 이상의 시간을 50일 연속으로 투자하는 것은 상당히 어려운 일이라는 것을 배우게 되었다.
하지만, 해당 환급 이벤트 때문에 진행한 것도 있지만 패스트 캠퍼스 강의를 듣는 수강자 모두에게 추천하고 싶은 이벤트이다.
돈을 떠나서 매일 1시간 이상을 투자하여 공부할 수 있는 구조이기에 이것만큼 효과적인 공부 스케쥴은 없는 것 같다. 그리고 어느 정도 강제성이 부여되어야 공부를 하게되는 사람이라(개인 마다 차이가 있을 수 있다) 너무나 좋은 효과를 얻어간다.
이번 후기는 크게 4가지 단계로 설명을 이어나가고자 한다.
1. 시작
누구에게나 시작은 두렵지만 설레는 법이다. 나에게 패스트캠퍼스 챌린지의 시작은 두려움 보다는 설레임이 더 가득했다. 이유는 태어나서 IT 관련 인터넷 강의를 처음 들어보는 것이기 때문이었다. 예전 강의를 녹화해 두어 함수나 최근 이슈랑은 많이 동떨어진 강의가 아닐지 아니면 너무 어려운 강의라 내가 이해하지 못할지 살짝 두려움이 있기는 했지만 처음 들어보는 강의이기에 설레임을 앉고 첫 강의를 수강하였다.

위 사진은 가장 첫 날 컴퓨터 셋팅을 하고 있는 사진이다.
처음 강의는 여느 IT 강의도 그렇겠지만 환경 셋팅으로 시작되었다. 첫 날에 컴퓨터 셋팅을 하면서 꼭 챌린지에 성공하자고 다짐을 하며 하나하나 놓치지 않기 위해 열심히 들었던게 생각이 난다. 그렇게 anaconda 셋팅 부터 jupyter 까지 셋팅을 완료하고 나서는 강사님이 준비하신 github에 들어가 강의자료를 다운로드 받았다.
강의 자료는 2가지 종류로 구성되어 있었다. 마크다운 형식의 강의자료와 실습코드로 각각 챕터마다 1개씩이 준비되어 있었다.
각각의 성격은 확실했다. 강의 자료는 이론 위주의 수업을 진행할 때 필요한 자료이고 실습코드는 강의 중에서 실습코드를 활용하여 강의해주시는 부분에서 필요한 자료이다. 둘 다 마크다운 형식을 기반으로 작성되어 있어서 나름 익숙한 타입이여서 보기 편했다.
(추가로 마크다운 어떻게 작성하는지도 확인할 수 있는 점이 좋았다.)
나는 처음에 주피터 노트북을 사용하다가 몇 년전 주피터 랩을 사용하고 있는 사용자인데, 이번에 셋팅하면서 많은 것을 배웠다. 강사님께서는 주피터 내에서 다양한 기능들을 추가해서 사용을 하고 계셨다.
해당 기능들은 좀 더 강의를 수강하기 위해 편한 기능들을 추가로 적용해 놓았지만 이후 계속해서 해당 셋팅으로 사용할 것 같다. 그리고 추가로 패키지들도 다양하게 사용할 것인데 해당 버전들이 각기 상이했다.
해당 강의에서는 어떤 패키지를 어떤 버전으로 사용할 것인지 미리 알려주어 셋팅 시간에 버전에 맞게 설치하는 시간을 가졌었다. 이 부분은 많이 유익했다. 왜냐하면 강의를 녹화한지 시간이 지나있을 텐데 그때 패키지에 새로운 버전이 나오면 그 버전에 맞게 코드가 수정되어야하기에 애초에 강의 내용 및 실습 코드가 구성되었던 버전을 미리 알려주어 해당 버전으로 다운로드하는 것이 굉장히 좋은 점이었다고 생각한다.
코딩 언어에 대한 강의들은 해당 강의 처럼 초기 셋팅에 사용하는 패키지들의 버전을 미리 알려주고 동일한 버전으로 셋팅하는 시간을 가지는 것이 좋을 것 같다.
2. 강의
처음 파이썬에 대한 기본 적인 강의가 이어질 줄 알았으나 해당 부분은 굉장히 금방 지나갔다. 이 부분이 굉장히 만족스러웠다. 어떤 책을 보든 어떤 강의를 들어도 처음에는 파이썬에 대한 기본적인 강의를 진행한다. 하지만, 해당 강의를 수강할 정도의 사람이라면 파이썬은 어느 정도 다루어본 사람들이 수강을 할 것이라 기본 파트는 최대한 빨리 지나갔던 것 같다. 해당 부분이 너무 만족스러웠고 그렇게 본격적인 강의가 시작되었다.
나는 처음부터 시계열(time series, 時計列)에 대한 기본 개념부터 잡고 들어갈 것이라 예상했다. 하지만, 나의 예상과 달리 데이터 분석 자체의 개념부터 시작되었다. 물론 내가 데이터 분석 전문가가 아니기에 다시 한번 리마인드하는 시간을 가지는 것이 싫지만은 않았다.
분석에 대한 기본 개념 및 프로세스를 확립하고 가는 강의에서 내가 알고 있었지만 헷갈렸던 부분과 잘못알고 있었던 부분을 확인할 수 있는 시간이었다. 그렇게 새롭게 서칭을 하며 복습을 할 수 있었다.
그렇게 데이터 타입 부터 시작해 기초적인 통계 부분도 이해하고 넘어갈 수 있었다. 그렇게 이제는 시계열 데이터 분석을 해볼 수 있겠다! 라고 생각할 때 쯤 강의는 비시계열 데이터 분석에 대해서 알려주시기 시작했다.
시계열 데이터 분석 강의라고 해서 시계열 데이터에 대해 다룰 줄 알았지만 비시계열 데이터에 대한 충분한 설명을 진행한 뒤 시계열 데이터에 대해 강의가 시작되었다.
처음에는 언제쯤 시계열 데이터를 다루어 볼 수 있을까 라는 의문을 품었지만 비시계열 데이터 분석을 어떻게 하는지 알아야 그것을 기준으로 비교하며 차이점을 확연히 인지하며 시계열 데이터 분석을 하는 것이 더 효과적이었다.
그 당시에는 얼른 시계열 데이터를 다루고 싶었지만 이러한 사전 작업을 통해 더 깊게 시계열 데이터를 이해할 수 있어서 좋았던 부분이었다.
이러한 강의 방식은 시계열 데이터에 대한 강의를 처음 듣는 사람에게 많은 도움이 되는 방식의 강의인 것 같다. 나도 비시계열 데이터 모델링의 경험은 있지만 시계열 데이터 모델링의 경험은 없기에 강의를 신청한 것이었다.
이러한 부분이 어느 정도 해소되면서 강의를 들을 수 있기에 데이터 분석을 시작하는 분들에게도 강추할 강의이다.
강의를 듣다가 종종 모르는게 있을 때는 인터넷 서칭을 통해 알아보며 예제 데이터로 실습코드들을 작성해보는 시간을 따로 가졌었다.
이렇게 중간 중간에 모르는게 있을 때 찾아보고 강의를 듣고 나서 또는 듣는 도중 데이터가 어떻게 변화하는지 파라미터를 수정해보면서 이해하는 시간을 가졌었다. 이러한 시간들이 쌓이고 쌓여 점차 내공이 쌓여가는 느낌이었고 공부도 잘 되었다.
그리고 중간 중간에 강사님께서 만약에 해당 내용들이 이해가 안간다면 어디를 참고하고 오라고 정확히 찍어주시는 부분이 좋았고 단원 마다 마무리하는 챕터들이 존재한다. 해당 파트에서는 복습을 하는 시간인데 한번 쫙 정리를 해주고 그 이후에 이런 부분 중 이해가 가지 않은 부분이 있거나 헷갈리는 부분이 있으면 강의를 멈추고 다시 어디부터 보라고 말씀해주신다. 한 두번 정도는 강의를 멈추고 주말에 따로 복습하는 시간을 가졌었는데 이러한 중간에 점검 단계가 있는 것이 강의에 많은 도움이 되었다.
이러한 과정은 챕터가 마무리되는 부분에만 있는 것이 아니다. 새로 시작될 이론이나 새롭게 시작되는 챕터들에서도 동일하게 과거에 배운 이론을 설명해주고 혹시라도 까먹거나 기억이 안난다면 몇 챕터 어디로 가셔서 해당 강의를 또는 해당 강의 자료를 보고 복습하고 오라고 상세하게 설명해주신다. 이로써 복습을 하고 오면 이후 강의들이 쉽게 이해가서 중간 중간 윤활유 같은 역할을 톡톡히 해내고 있는 모습을 마주했다.
3. 추후 계획
이렇게 시계열 데이터 분석에 대한 공부를 마쳤다. 처음으로 듣는 시계열 데이터에 관련된 인터넷 강의였다. 물론 it관련 강의자체가 처음이었지만 정말 도움이 많이 되었다. 수강은 끝났지만 중간 중간 이해하지 못하고 넘어간 부분들도 존재한다. 그래서 복습을 다시 한번 진행해볼 예정이다.
아마 중간에 시계열 데이터를 다루기 시작하면서 전처리 부분부터 다시 한번 쭉 복습을 해야할 것 같다. 그리고 나서 실제 kaggle 데이터 중 시계열 데이터를 하나 골라서 모델링을 진행해볼 예정이다. 중간 중간 모르거나 방향성이 애매할 때는 다시 패스트캠퍼스 강의로 돌아와 복습하고 방향성을 찾아서 다시 나아가고 이러한 일련의 과정을 거치며 시계열 데이터에 대한 이해와 실력을 늘려나갈 계획이다.
한마디로 시계열 데이터에 대한 근본적인 이해를 마쳤고 이제는 실무 데이터를 다루어보며 다시 복습하고 이러한 일련의 과정을 거치며 더 성장하는 데이터 분석가가 될 예정이다.
그리고 내 블로그 글을 본 사람들은 알겠지만 자동매매프로그램의 알고리즘을 시계열 모델링을 통한 하나의 지표를 구축할 예정이다. 물론 어려운 부분이지만 포기하지 않고 끝까지 작업을 진행해보려고 한다.
우선은 통계모델링 부터 시작해서 딥러닝까지 모두 구축해서 각각의 효율이 어느정도인지 테스트를 해보면서 최종적으로 자동매매프로그램을 구축하고자 한다.
그럴려면 많은 시간도 소요될 것이고 시계열 딥러닝 쪽을 좀 더 공부해야할 필요성이 있을 것 같다. 이 다음 시계열 공부는 책으로 할지 아니면 패스트 캠퍼스에 적합한 강의가 있다면 또 인터넷 강의로 진행할 지 그것은 추후에 정해질 것 같다.
4. 느낀점
처음에 50일 챌린지가 그렇게 버거울까? 라고 생각했었는데 날이 갈 수록 직장인들에게 매일매일 무엇을 한다는 것 자체가 엄청 고된 일이구나 느끼게 되었다. 물론 공부를 잘하시는 분들은 이러한 미션 없이도 공부를 잘 하실 수 있겠지만 평소에 공부 습관이 제대로 구축되어 있지 않은 나는 이러한 챌린지가 꼭 필요한 사람이었다.
그렇게 너무 힘든 순간이 많았다. 사실 다음날 저녁에 술 마실 약속이 있으면 어떻게든 저녁에 작성을하고 다음 12시 넘어 새벽에 바로 데일리 미션을 진행하는 식으로...결국 11시 부터 1시까지 각각 데일리 미션을 연속해서 진행하고 나서 잠을 청했던 날들이 종종 있었다.
그리고 나는 지방에 파견을 나와 있기에 서울에 올라가는 일이 있으면 PC가 없어 따로 강의를 들으며 블로그를 작성하는 작업이 어려운 부분이 있었다. 그렇기에 어디서든 강의를 수강할 수 있고 블로그 글을 작성하며 코드르 실행해 볼 수 있도록 환경을 만들어 두었다.
어디서든 수강을 하고 블로그 글을 작성할 수 있도록 블루투스 키보드를 구매하여 태블릿 pc를 이용하여 어디에서나 강의를 수강하고 블로그 글을 작성하였다.

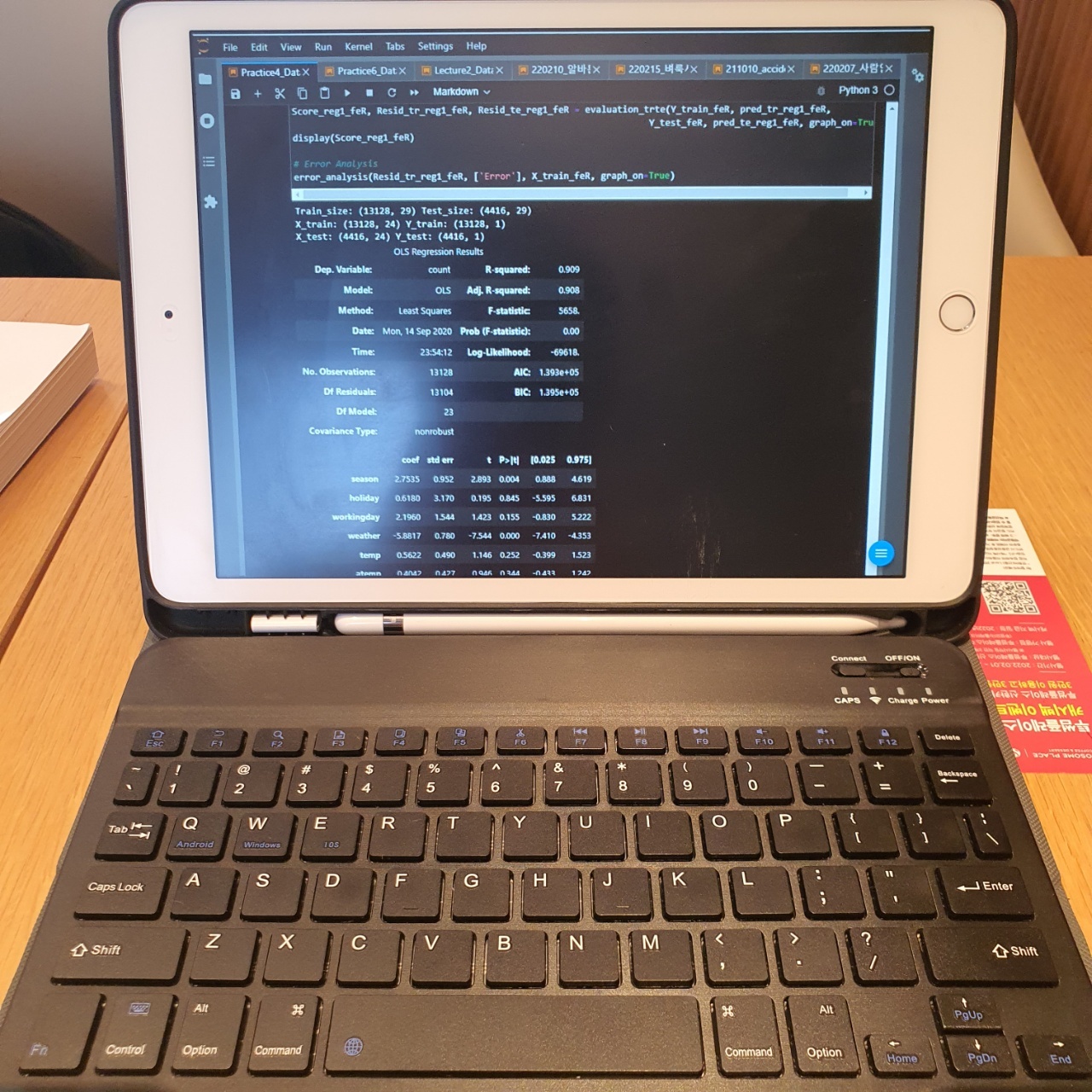
본가, 카페, 지하철 등 다양한 곳에서 강의를 수강하며 블로그글을 작성해왔다.
그리고 태블릿 자체에서 코딩을 하기 힘들어 자취방 pc를 항상 켜두고 크롬 원격을 접속해두며 태블릿 pc로 원격으로 로컬 pc에 접속해서 주피터 노트북에 있는 코드들을 실행하며 외부에서 공부를 진행했다.
돌이켜 생각해보면 이러한 각오를 가지고 챌린지에 참여하면 어떤 도전이든 성취할 것 같다는 생각이 든다...그리고 후기를 블로그 글을 쓰다보니 블로그에 대한 공부도 더 하게 되었다.
그래서 기존에 운영중이던 블로그였지만 좀 더 본격적으로 관리해볼까 라는 생각이 들어 카테고리도 나누고 덕분에 블로그를 잘 관리할 수 있게 되었다.
여러모로 챌린지가 내 다방면으로 도움을 준것같다는 생각이 든다. 내 지인 중 누군가 패스트 캠퍼스 강의를 들을 예정이라면 해당 챌린지를 꼭 추천하고 싶다. 그리고 분석 쪽 강의를 듣고자 한다면 내가 들었던 강의를 또 추천하고 싶다.
이 만큼 상세하게 잘 알려주는 강의도 드물 것 같고 실습 데이터를 기반으로 이렇게 하나 하나 코드까지 집어주는 강의는 꽤 드물다고 생각한다.
막상 4천자를 채우려고 시작했을 때는 덜컥 겁이 났지만 막상 쓰고 나니 여태까지 도전했던 나의 50일을 정리하는 것 같아 기분이 좋다.
뒤돌아보니 굉장히 뿌듯한 챌린지였다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 50일차 (0) | 2022.03.14 |
|---|---|
| 패스트캠퍼스 챌린지 49일차 (0) | 2022.03.13 |
| 패스트캠퍼스 챌린지 48일차 (0) | 2022.03.12 |
| 패스트캠퍼스 챌린지 47일차 (0) | 2022.03.11 |
| 패스트캠퍼스 챌린지 46일차 (0) | 2022.03.10 |



