
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝
- 직장인자기계발
- 패캠챌린지
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 패스트캠퍼스
- 상관분석
- 독서리뷰
- It
- airflow
- 데이터분석
- 직장인인강
- 리뷰
- 패스트캠퍼스후기
- 챗지피티
- Ai
- 활성화함수
- 머신러닝
- 데이터
- API
- DAGs
- 태국여행
- Python
- 분석
- 방콕여행
- 파이썬
- 빅데이터
- 자동매매프로그램
- nlp
- 클라우드
- ChatGPT
- Today
- Total
데이터를 기반으로
패스트캠퍼스 챌린지 35일차 본문
오늘은 강의 들을 시간과 블로그 글을 쓸 여유가 안되어 지하철에서 수강하며 글을 써서 인증샷이 다소 협소한 점 이해부탁드립니다.

테블릿으로 강의를 들으며 블로그에 정리하는 중의 사진입니다. 사진상은 수강중인 화면입니다.
오늘의 강의는 Bagging 과 Boosting 알고리즘과 시계열 알고리즘의 비교에 대한 설명으로 시작되었다.
강사님께서는 이전 강의에서 Cost Function때문에 좀 더 구체적인 설명을 했었다고 한다. 우리는 일반적으로 Cost Function을 고려하지 않는다고 한다. 이유는 너무 알고리즘 자체에만 포커싱을 가지고 고민을 하기 때문이라고 한다.
하지만, 실질적으로 알고리즘 성능을 향상시키는 것은 Cost Function으로 인해 일어난다고 한다.
위 화면은 강의화면입니다.
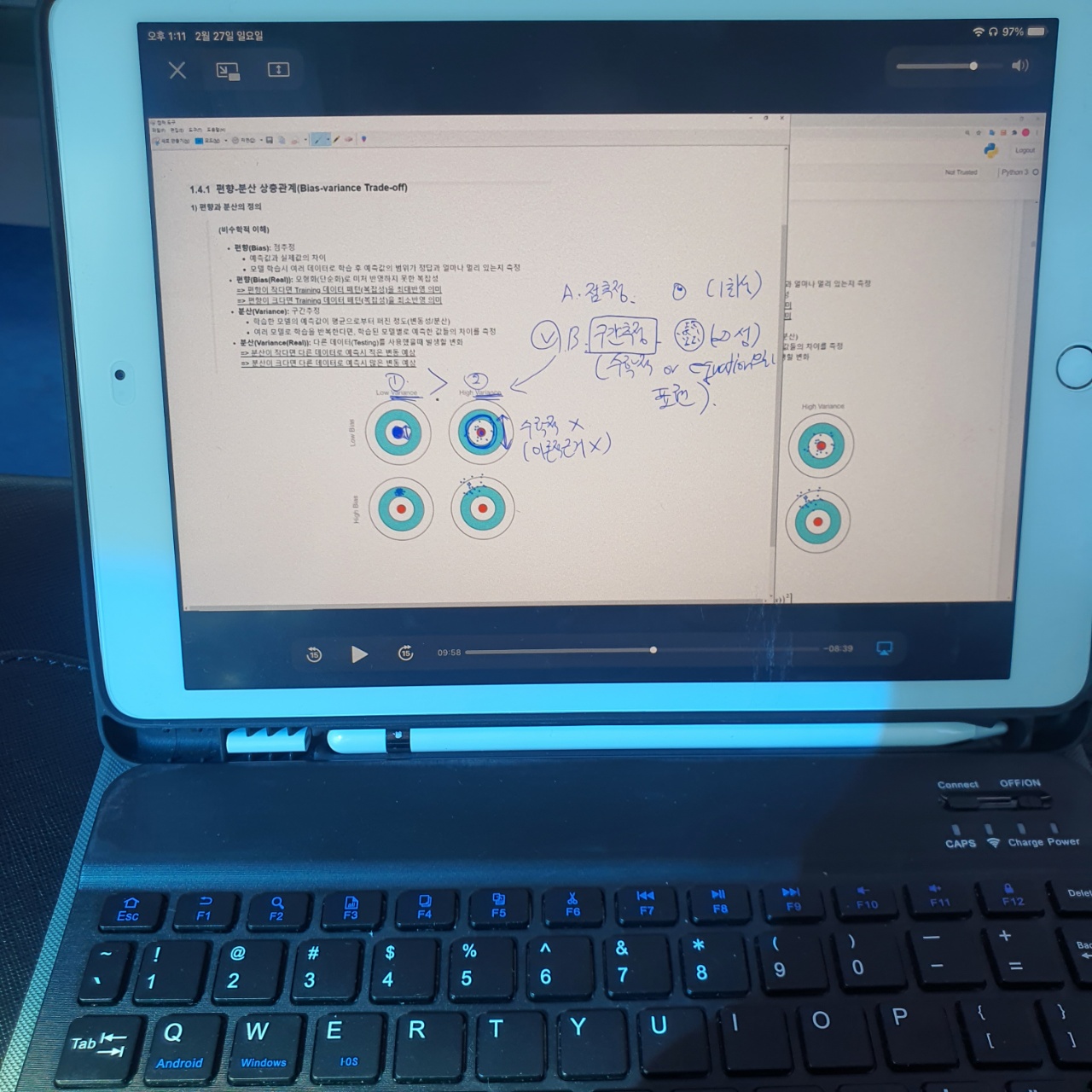
우리가 이전 강의에서 비시계열 알고리즘에 대한 공부를 했을 때 분산과 편향에 대해 배웠던 적이 있다. 강사님은 이번에 시계열에서 배운 부분과의 차이점을 보여주기 위해 기존 강의 자료를 캡쳐하며 설명을 이어나갔다.
왼쪽 상단과 오른쪽 상단의 그림을 비교해보면 둘 다 평균은 동일하다. 이유는 빨간색 점을 중심으로 구성되어 있기에 평균은 동일하다. 하지만, 퍼진 정도가 다르기에 분산이 다르다고 한다. 우리는 이를 이전 강의에서 점추정과 구간추정 중 구간 추정이라고 불렀다.
점 추정은 1회성이고 구간 추정은 무한대로 시도를 해보며 구간이 어느 정도 정해지기에 구간을 추정하는 것인데 데이터 마이닝에서는 이러한 것을 구간 추정이라 하지 않고 분산이라고 부르는 이유는 통계적 근거가 부족하여 해당 현상을 구간 추정이라 표현하지 않는다고 한다.
두 번째 편향 부분은 왼쪽 상단 그림과 왼쪽 하단의 그림을 보면 두 개다 같은 곳을 맞추었지만 빨간 점에서 이탈해 있는게 하단 그림이다. 이러한 것을 보통 한 곳의 점을 찍은 것과 같아 점 추정이라고 표현하지만 데이터마이닝에서는 구간추정과 같이 통계적 근거가 부족하여 편향이라고 부른다.
점추정, 구간추정은 시계열 데이터 분석에서는 통계적 근거가 있어 이렇게 불렀기에 데이터 마이닝과의 차이가 존재했었다.
Bagging은 분산을 줄이기 위해 사용되며 Boosting은 편향을 줄이기위해 보통 사용된다. 편향과 분산이 큰 곳에서 다이렉트로 둘다 줄이는 방법은 없다고 한다. 이상적으로 배깅과 부스팅을 왔다 갔다하며 모형을 정확히 만든다고 한다.
※ 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성었습니다.
※ 관련 링크 : https://bit.ly/37BpXiC
'스터디 > 패스트캠퍼스' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 37일차 (0) | 2022.03.01 |
|---|---|
| 패스트캠퍼스 챌린지 36일차 (1) | 2022.02.28 |
| 패스트캠퍼스 챌린지 34일차 (0) | 2022.02.26 |
| 패스트캠퍼스 챌린지 33일차 (0) | 2022.02.25 |
| 패스트캠퍼스 챌린지 32일차 (0) | 2022.02.24 |



