
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 리뷰
- airflow
- 독서리뷰
- GPT
- 클라우드
- 데이터분석
- 파이썬을활용한시계열데이터분석A-Z올인원패키지
- 개발자
- 딥러닝
- 직장인인강
- llm
- 패스트캠퍼스후기
- 직장인자기계발
- 데이터
- 방콕여행
- Ai
- 챗지피티
- Python
- 패캠챌린지
- Agent
- 머신러닝
- data
- It
- API
- 태국여행
- 파이썬
- 빅데이터
- 상관분석
- nlp
- 패스트캠퍼스
- Today
- Total
데이터를 기반으로
R 스터디 1일차 - Plot 본문
첫 번째 과제 Plot
스터디 첫 번째 과제는 plot 을 이용해보는 것이었습니다.
편의상 코드의 색은 파란색으로 하겠습니다다.
rm(list=ls())
기존에 있는 변수들이 있길래 지우고 시작했습니다.
자 이제 본격적으로 시작해보자!!
데이터 생성부터 시작해보겠습니다.
library(ggplot2)
#ggplot 패키지에 내재되어 있는 iris 데이터를 이용해 진행할 예정입니다.
data1<-iris$Sepal.Length
data2<-iris$Sepal.Width
data3<-iris$Petal.Length
data4<-iris$Petal.Width
#각각의 컬럼을 데이터 분할 했습니다.
plot(data1)
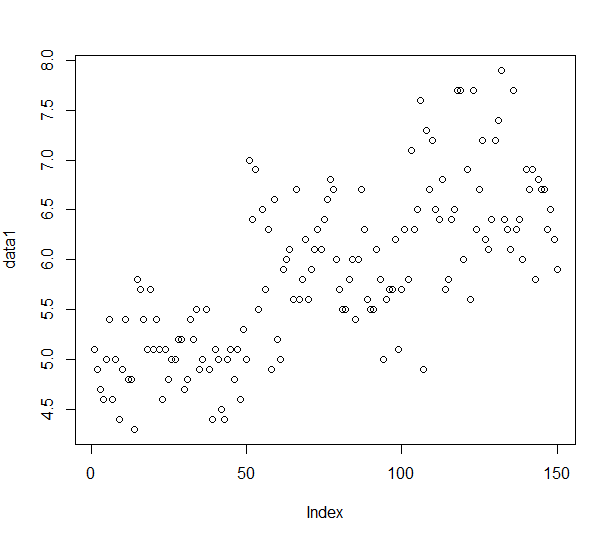
Sepal.Length의 산점도 입니다.
plot(data1,pch=15)
#pch는 산점도에서 각각의 점의 모양을 바꿀 수 있습니다.

pch의 숫자별 모양
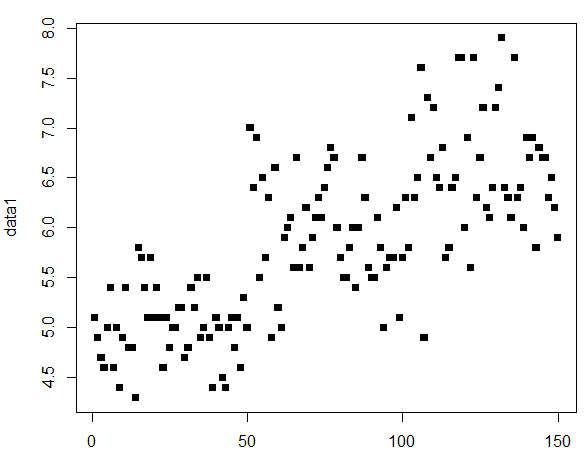
pch=15로 설정하여 Sepal.Length의 산점도를 그렸습니다.
plot(data1,pch=20,cex=1)
#cex의 값이 클 수록 점이 커집니다.
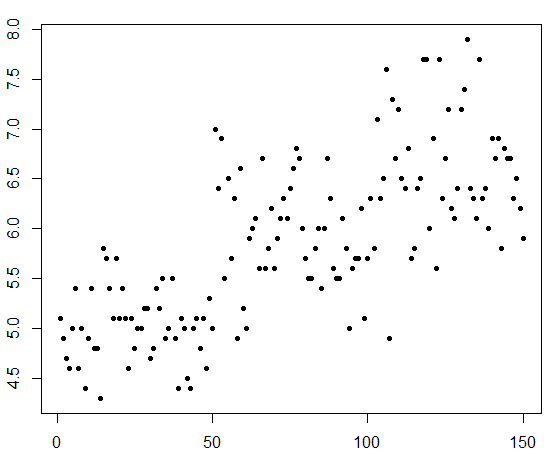
.
plot(data1,pch=20,cex=1,type="l")
#type=l 은 선 입니다. 밑을 보면 알파벳으로 타입을 설정할 수 있습니다.

type의 종류
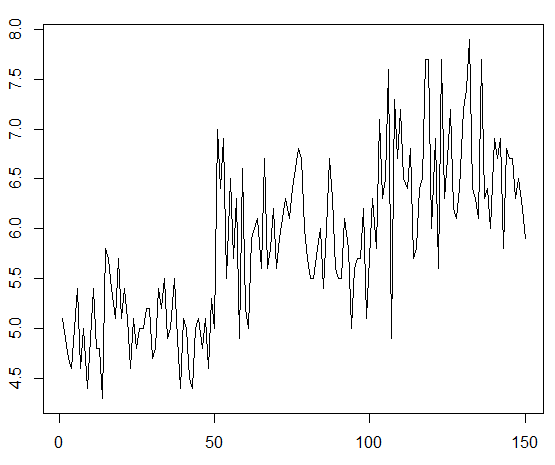
type="l"
plot(data1,pch=20,cex=1,type="l",xlab="x",ylab="y")
# x축과 y축의 이름을 설정할 수 있습니다.
x축과 y축의 이름 설정
plot(data1,pch=20,cex=1,type="o",xlab="x",ylab="y",main="Plot study")
# main은 상단의 제목을 설정할 수 있습니다.
 .
.abline(h=5,col="red")
#h는 가로선, v는 세로선을 그을 수 있고 값은 선을 그을 위치의 값을 의미합니다.
 .
.colors()
#R의 내재되어 있는 색은 총 657가지 입니다.

abline(v=50,col="blue")
#위에 가로선 설명을 보시면 됩니다.
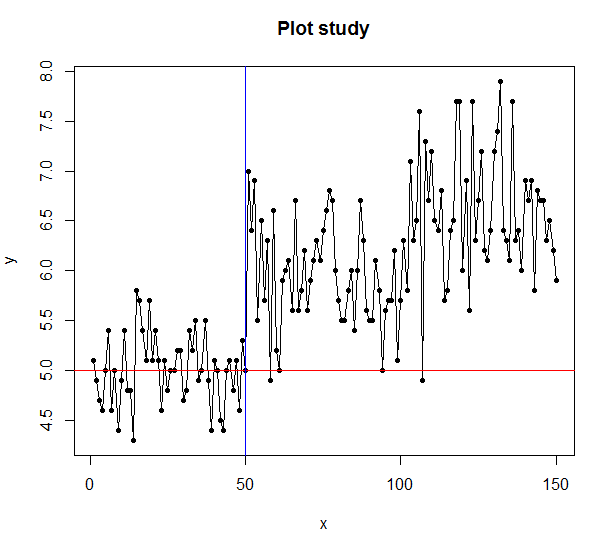
abline(a=4.5,b=0.02,col="green")
#a는 y절편, b는 기울기
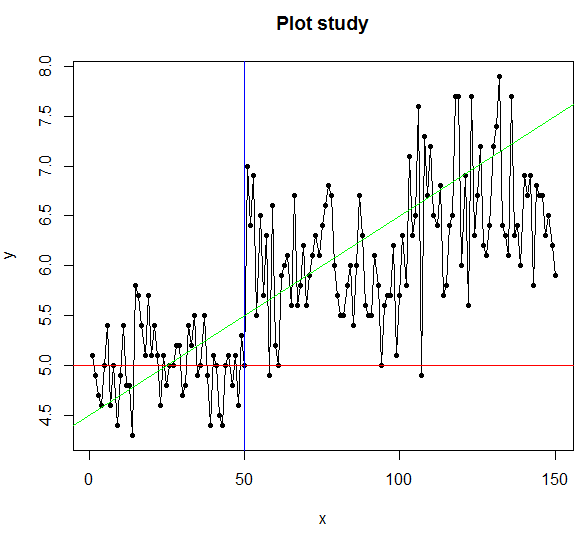
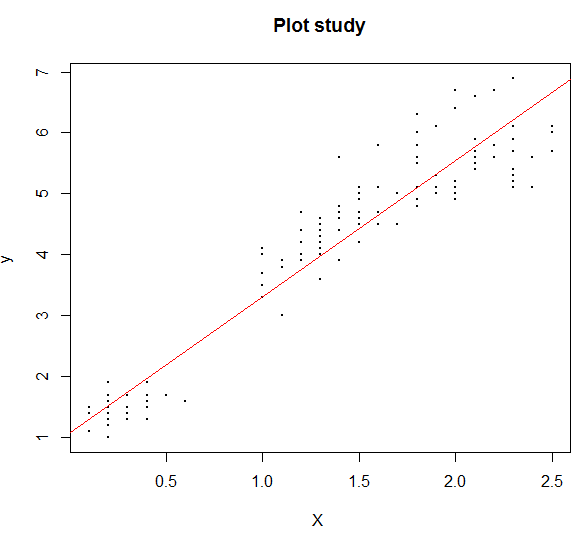
plot(x=data4,y=data3, pch=20, cex=0.5, type="p", xlab="X ", ylab="y ", main="Plot study")
abline(lm(data3 ~ data4), col="red")
#회귀식 그릴 때 형태는 lm(y~x)
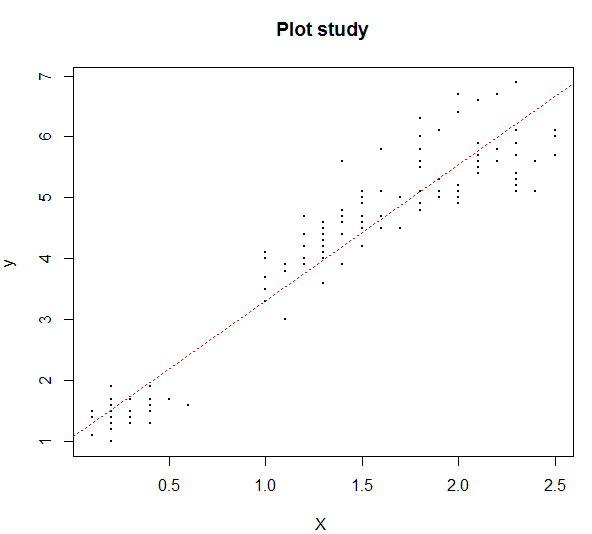
abline(lm(data3 ~ data4), col="red", lty=3)
# lty로 선의 유형 선택 가능

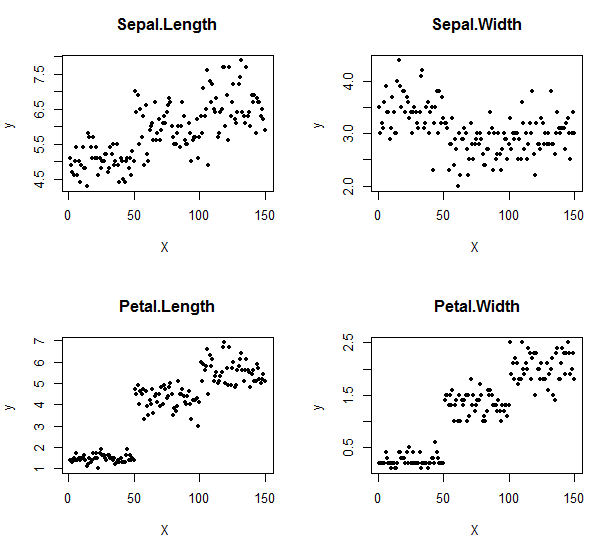
par(mfrow=c(2,2))
plot(data1, pch=20, cex=1, type="p", xlab="X ", ylab="y ", main="Sepal.Length")
plot(data2, pch=20, cex=1, type="p", xlab="X ", ylab="y ", main="Sepal.Width")
plot(data3, pch=20, cex=1, type="p", xlab="X ", ylab="y ", main="Petal.Length")
plot(data4, pch=20, cex=1, type="p", xlab="X ", ylab="y ", main="Petal.Width")
#개인적으로 4개의 그림이면 2,2 가 더 이상적으로 보입니다.
par(mfrow=c(1,1))
#다시 1개로 크게 보고 싶어서 이 코드를 썼지만 좀 더 간편한 코드가 있을 것 같다고 생각됩니다. 찾아봐야겠습니다.
plot(data1, pch=20, cex=1, type="p", xlab="X ", ylab="y ", main="Sepal.Length")
par(new=TRUE) #그래프 겹쳐보이게 해줍니다.
plot(data3, pch=20, cex=1, col="red", type="p", xlab="X ", ylab="y ", main="Petal.Length")
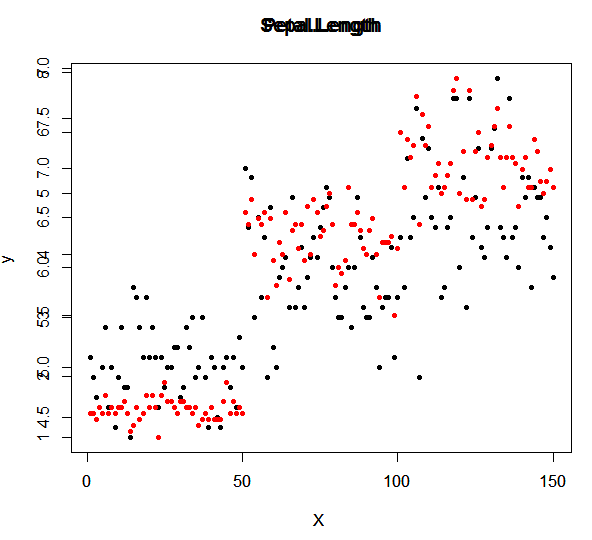
#그리고 나서 확인해보니 타이틀과 y축의 값들이 일치하지 않아 기준이 모호해 두 산점도의 비교가 힘들다고 생각됩니다.
#그래서 y축의 값들을 통일시키려 합니다. ylim 을 이용해서!
plot(data1, pch=20, cex=1, type="p",
xlab="X ", ylab="y ", main="",
ylim=c(1,7.5))
par(new=TRUE)
plot(data3, pch=20, cex=1, type="p",
xlab="X ", ylab="y ", main=" ", col="red",
ylim=c(1,7.5))
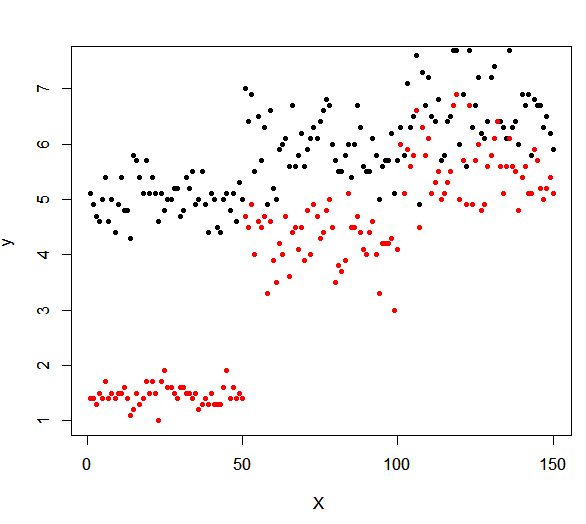
# y축의 값을 통일하고 보니 아까와는 다른 그림이 나왔습니다. 첫 번째걸로 그대로 해석을 했다면 오류가 있었을 것으로 생각됩니다.
# 그림 저장에 앞서 저장 위치를 확인해 보았습니다!
png("plot down.png",width = 950, height = 650,unit="px")
par(mfrow=c(1,1))
plot(data1, pch=20, cex=1, type="p",
xlab="X ", ylab="y ", main="",
ylim=c(1,7.5))
par(new=TRUE)
plot(data3, pch=20, cex=1, type="p",
xlab="X ", ylab="y ", main=" ", col="red",
ylim=c(1,7.5))
dev.off()
#png 파일로 저장이 되었습니다.
#이 부분 부터는 번외라고 하셔서 돌려보았지만 좀 더 이해하기 위해 더 공부를 해봐야할 것 같습니다!
#함수 적용
trend_data <- function(x) {
# sapply를 사용해 data가 숫자 인지 Check를 한다.
numeric_test <- sapply(x,is.numeric)
# 이 숫자들의 위치를 찾는다.
numeric_index<- which(numeric_test)
# 숫자들의 위치를 다시 조합하여 숫자들만 있는 data set을 만든다.
numeric_data <- x[,numeric_index]
# 이를 시각화 할때 컬럼의 이름을 파학하기 위해 colnamea_data라고 저장해준다.
colname_data <- colnames(numeric_data)
# par(mfrow=c(행,열) 행, 열을 표현할것인데 1~16개의 컬럼까지 모두 커버 할 수 있도록 다음과 같이 표현을 할 것이다.
if(ncol(numeric_data) == 1) {
# 컬럼 1개 = 1행 1열
low_count <- 1
col_count <- 1
} else if(ncol(numeric_data) == 2) {
# 컬럼 2개 = 1행 2열
low_count <- 1
col_count <- 2
} else if(ncol(numeric_data) == 3) {
# 컬럼 3개 = 1행 3열
low_count <- 1
col_count <- 3
} else if(ncol(numeric_data) == 4) {
# 컬럼 4개 = 2행 2열
low_count <- 2
col_count <- 2
} else if(ncol(numeric_data) %in% c(5:6)) {
# 컬럼 5~6개 = 2행 3열
low_count <- 2
col_count <- 3
} else if(ncol(numeric_data) %in% c(7:9)) {
# 컬럼 7~9개 = 3행 3열
low_count <- 3
col_count <- 3
} else if(ncol(numeric_data) %in% c(10:12)) {
# 컬럼 10~12개 = 3행 4열
low_count <- 3
col_count <- 4
} else if(ncol(numeric_data) %in% c(13:16)) {
# 컬럼 13~16개 = 4행 4열
low_count <- 4
col_count <- 4
}
par(mfrow=c(low_count,col_count))
for(i in numeric_index) {
plot(numeric_data[,i], pch=20,ylab="", cex=1, main=colname_data[i])
}
}
trend_data(cars)
trend_data(iris)
------------------------------------------------------------------------------------------------------------------------------------------------------------------
'스터디 > R 온라인 스터디' 카테고리의 다른 글
| R 스터디 4일차 - 시각화!!(feat. ggplot) (0) | 2019.04.29 |
|---|---|
| R 스터디 3일차 - 다양한 시도와 접근!(중국집&피자) (0) | 2019.03.23 |
| R 스터디 2일차 - 데이터 확인, 데이터 다각도로 보기! (2) | 2019.03.12 |


